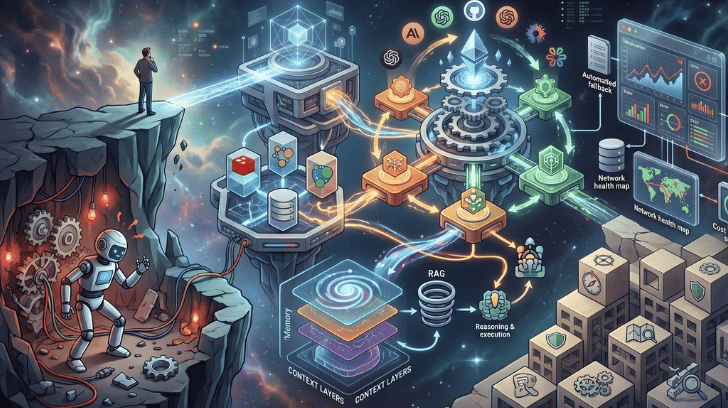
El verdadero reto ya no está solo en los LLM, sino en la arquitectura que los conecta con el conocimiento real de la empresa. Tecnologías como embeddings, bases de datos vectoriales y arquitecturas RAG permiten transformar datos en respuestas fundamentadas y decisiones más fiables. Entender esta arquitectura es clave para llevar la inteligencia artificial del laboratorio a la operación empresarial.
Por qué el modelo ya no es lo más importante en la IA empresarial
Hace apenas unos años la conversación giraba en torno a “qué modelo es mejor”.
Hoy, en entornos empresariales, esa ya no es la pregunta correcta.
El verdadero diferencial no está en el LLM aislado, sino en la arquitectura que lo rodea.
Un modelo potente sin contexto es solo un generador avanzado.
Un modelo conectado a conocimiento estructurado es un sistema de decisión asistida.
Y ahí es donde convergen tres elementos que están redefiniendo la ingeniería moderna:
- LLMs de última generación
- Embeddings semánticos
- Bases de datos vectoriales integradas en arquitecturas RAG
Cuando se combinan correctamente, la IA deja de “responder” y empieza a fundamentar.
Qué es un LLM y cuáles son sus limitaciones en entornos corporativos
Un LLM (Large Language Model) es un modelo de inteligencia artificial entrenado con enormes volúmenes de texto para aprender patrones del lenguaje.
Desde un punto de vista técnico:
- Predice la siguiente palabra en función del contexto previo.
- Captura relaciones semánticas complejas.
- Aprende estructuras sintácticas, lógica discursiva y patrones técnicos.
- Puede razonar en múltiples pasos si el prompt está bien diseñado.
Ejemplos relevantes en 2026:
- GPT-5.2
- Claude 3 Opus
- Gemini 1.5 Pro
- Llama 3
Cada uno tiene fortalezas distintas (razonamiento técnico, contexto largo, multimodalidad, despliegue local).
Pero todos comparten una limitación clave:
No tienen acceso nativo a tu conocimiento corporativo interno.
Y ahí empieza el verdadero problema en entornos empresariales.
¿Qué es RAG y por qué cambia el paradigma?
RAG (Retrieval-Augmented Generation) es un patrón arquitectónico que añade una fase de recuperación de información antes de que el modelo genere la respuesta.
En lugar de confiar únicamente en lo que el modelo “recuerda” de su entrenamiento, el sistema:
- Convierte la pregunta en un embedding.
- Busca fragmentos relevantes en una base de datos vectorial.
- Inyecta esos fragmentos como contexto en el prompt.
- El LLM genera una respuesta fundamentada en esos datos.
Es decir:
- LLM solo → Respuesta probable.
- LLM + RAG → Respuesta contextualizada y trazable.
RAG no es un modelo nuevo. Es una arquitectura que conecta el modelo con tu conocimiento real.
Embeddings: la capa matemática que lo hace posible
Para que RAG funcione, necesitamos convertir textos en vectores numéricos de alta dimensión llamados embeddings.
Estos vectores representan significado, no palabras exactas.
Gracias a ello:
- “Factura anulada” y “cancelación de póliza” pueden estar cerca
semánticamente. - Fragmentos técnicos relacionados se agrupan, aunque no compartan términos
exactos. - La búsqueda se vuelve conceptual, no literal.
Sin embeddings, la recuperación sería puramente sintáctica.
Con embeddings, la recuperación es semántica.
Bases de datos vectoriales: la memoria estructurada
Aquí entran motores especializados en almacenar y consultar vectores de forma
eficiente.
- Qdrant
- Especialmente sólido en producción por:
- Búsqueda ANN optimizada.
- Filtrado avanzado por metadatos.
- Buen encaje en arquitecturas .
- NET y microservicios.
- Pinecone
- Enfoque SaaS gestionado, ideal para escalabilidad cloud-native.
- Weaviate
- Interesante por su búsqueda híbrida (vectorial + keyword) y flexibilidad
de integración.
- Interesante por su búsqueda híbrida (vectorial + keyword) y flexibilidad
Caso aplicado: modernización de sistemas legacy
En migraciones tecnológicas complejas, el reto no es solo traducir código.
Es entender el contexto acumulado durante años.
Un enfoque RAG permite:
- Indexar código fuente y documentación histórica.
- Generar embeddings por fragmentos.
- Almacenar vectores segmentados por dominio.
- Inyectar únicamente contexto relevante al LLM seleccionado.
Resultados reales:
- Menor riesgo en refactorizaciones.
- Mejor análisis de impacto.
- Reducción de alucinaciones.
- Mayor trazabilidad técnica.
Aquí es donde la IA deja de ser experimental y se convierte en estratégica.
Arquitectura empresarial madura
Una arquitectura sólida debería incluir:
- Servicio desacoplado de embeddings.
- Base vectorial segmentada por dominio.
- LLM intercambiable (evitar vendor-lock total).
- Orquestador de prompts.
- Sistema de auditoría.
- Control de temperatura y determinismo.
- Estrategia de chunking optimizada.
- Re-ranking cuando sea necesario.
El modelo puede cambiar.
La arquitectura debe permanecer.
En proyectos de transformación digital donde la modernización es estructural, como ocurre en entornos impulsados por organizaciones como Raona, donde el foco está en el diseño arquitectónico sostenible, no en la moda tecnológica.
Riesgos que deben gestionarse
- Fugas de información sensible.
- Mala segmentación documental.
- Contaminación semántica.
- Falta de versionado de embeddings
- Dependencia excesiva de un proveedor.
Un LLM potente no compensa una mala arquitectura.
Conclusión: la nueva infraestructura de conocimiento empresarial
Un LLM es un motor de lenguaje avanzado.
RAG es la arquitectura que lo conecta con conocimiento real.
La combinación de LLM avanzado + embeddings + base vectorial representa una nueva capa de infraestructura empresarial.
No hablamos de asistentes conversacionales básicos.
Hablamos de sistemas que razonan sobre conocimiento corporativo.
Y eso redefine cómo diseñamos software, gestionamos información y aceleramos la
modernización tecnológica.