Cuando pensamos en deportes, generalmente imaginamos jugadas dinámicas, goles apasionantes y adrenalina pura. Pero detrás de esos momentos mágicos, hay una gran cantidad de datos esperando ser analizados. En este artículo, te mostraremos cómo Power BI se está convirtiendo en el compañero perfecto para desentrañar los secretos ocultos en esos datos deportivos.
Los datos
Las posibilidades son infinitas, pero debemos partir de un conjunto de datos. Para esta demostración hemos usado shot_logs, que ofrece un detallado registro de tiros en partidos de baloncesto, capturando desde el contexto del juego (como el ID del partido y la ubicación) hasta detalles específicos del tiro (como la distancia del tiro, el defensor más cercano y la identidad del jugador que realizó el tiro).
Visualización
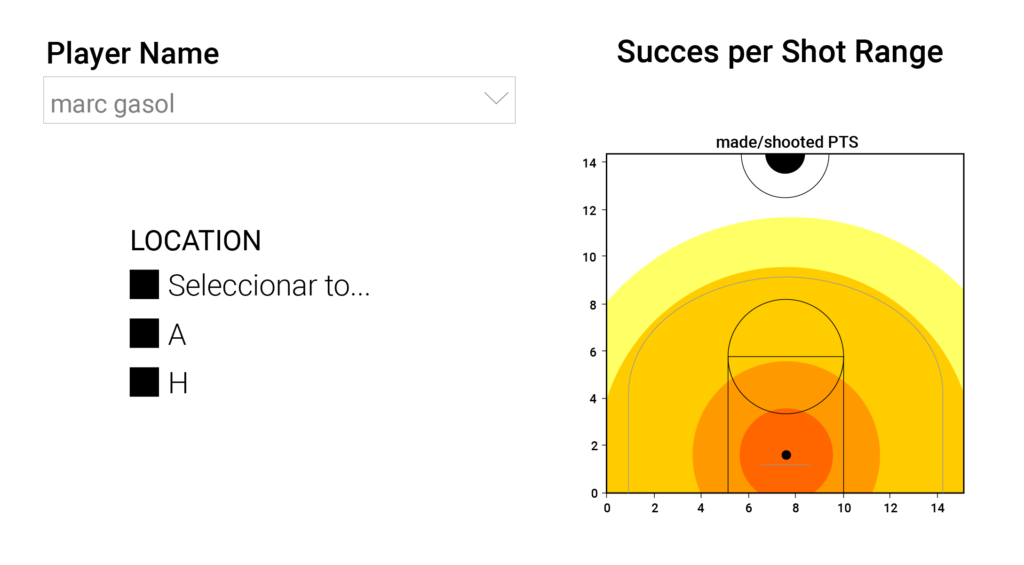
Usando tanto PowerBI como Microsoft Fabric, es posible tratar los datos obtenidos para crear gráficos personalizados que nos ayuden a analizar los puntos fuertes y débiles de los rivales. Un ejemplo lo podemos ver a continuación, donde creamos un gráfico desde Python, que distingue 5 rangos de tiro según la distancia a canasta y nos muestra el grado de acierto para cada jugador y rango. Se muestran datos de Marc Gasol y Stephen Curry, pero estos se calculan para todos los jugadores de forma simultánea, automatizando así gran parte de las tareas de análisis de un tirador, y generando un informe de cada jugador al alcance con un solo clic.



Synapse Data Science; Machine Learning en Fabric
Synapse Data Science te ayuda a crear rápidamente modelos de IA predictivos a escala e impulsa la colaboración durante el entrenamiento, la implementación y la administración de modelos de Machine Learning. Permite que científicos de datos accedan directamente a datos protegidos y gobernados preparados por equipos de ingeniería, evitando copias y garantizando acceso seguro.
Predicciones de tiro; Machine Learning aplicado
En este caso, el principal objetivo es obtener una predicción del resultado de un lanzamiento de juego de determinado jugador, teniendo en cuenta todos sus anteriores tiros, y sus circunstancias.
Basándose en ciertos factores como el tiempo restante en el reloj de tiro (SHOT_CLOCK), la distancia del tiro (SHOT_DIST) y la distancia del defensor más cercano (CLOSE_DEF_DIST), el modelo predice si un tiro será acertado o fallado, usando una regresión logística.
Procedimiento:
Se cargan y preprocesan datos relacionados con tiros en baloncesto. Estas características se normalizan y, posteriormente, los datos se dividen en conjuntos de entrenamiento y prueba. Utilizando el conjunto de entrenamiento, se entrena un modelo de regresión logística con la biblioteca scikit-learn, con el objetivo de predecir si un tiro sería acertado o fallido basándose en los factores mencionados.

Resultados y Conclusiones
Aplicando el modelo a todos los tiros registrados de Stephen Curry, obtenemos los siguientes resultados:

El modelo tiene un rendimiento moderadamente bueno al predecir tiros en baloncesto, con una ligera ventaja en identificar tiros fallidos sobre tiros acertados. La exactitud general de 61.38% sugiere que el modelo está haciendo predicciones correctamente más de la mitad del tiempo, notablemente mayor a lo que lo haría un modelo ingenuo. El equilibrio entre precisión y exhaustividad, representado por el F1-score, es razonablemente bueno para ambas clases, aunque nuevamente muestra un margen para mejora, especialmente en tiros acertados.