

En esta quinta entrega de la serie “Hablemos de…”, los Small Language Models (SLM) dejan de ser una curiosidad técnica para convertirse en un pilar realista de las arquitecturas empresariales modernas. En 2025 ya no hablamos solo de “llevar todo a la nube”: hablamos de equilibrio.
Para la mayoría de las tareas cotidianas como resumen, extracción, clasificación, recuperación aumentada (RAG) sobre documentación propia, asistentes de frontoffice o copilotos de dominio, los SLM ofrecen latencias bajas, control de datos y un coste predecible. Reservamos los modelos grandes para los retos que realmente lo exigen (multimodal pesado, cobertura abierta de conocimiento, razonamiento profundo y creativo a escala). El punto de madurez es claro: hay familias abiertas y bien mantenidas entre ~0.3B y ~8B parámetros que rinden con holgura en portátiles, estaciones de trabajo ligeras e incluso en dispositivos edge industriales.
A lo largo de este artículo repasaremos el panorama SLM a noviembre de 2025, desgranaremos arquitecturas relevantes para MVP y producción, cuantificaremos su huella de memoria (FP16 frente a cuantización INT8/INT4) y propondremos un marco de decisión, incluidos patrones de despliegue abiertos con vLLM/llama.cpp/MLX, para elegir con criterio cuándo un SLM basta y cuándo conviene promover a un LLM grande.
¿Qué es un SLM?
Un SLM no es “cualquier modelo pequeño”. Suele moverse en el rango sub10B (con un dulce entre 1B y 8B para producción local) y se entrena con curaduría de datos, técnicas de eficiencia y objetivos de uso pragmáticos.
No busca ganar benchmarks de mundo abierto; busca entregar valor con fricción mínima y con garantías operativas: arranque rápido, consumo de memoria razonable, compatibilidad con runtimes eficientes (llama.cpp, vLLM, MLX/Metal, OpenVINO) y, cada vez más, verificación de integridad del checkpoint. Por diseño, un SLM prioriza el tiempo a valor: reduce la distancia entre el “lo tengo instalado” y el “lo tengo integrado en mi flujo de trabajo”.
¿Por qué ahora? Coste, privacidad y latencia
El desplazamiento del cómputo hacia el dispositivo o el CPD propio responde a tres fuerzas. La primera es económica: en cargas previsibles y de volumen constante, la inferencia local recorta el coste por consulta y permite presupuestar con precisión.
La segunda es regulatoria y de confianza: mantener datos sensibles bajo el propio perímetro simplifica el cumplimiento y reduce la superficie de exposición. La tercera es técnica: acortar la distancia entre datos y modelo elimina viajes a la nube, baja la latencia y mejora la resiliencia ante redes intermitentes. El resultado no es antinube; es híbrido con cabeza: local por defecto, nube cuando aporta ventaja.
Panorama 2025 (selección curada)
La diversidad actual habilita elegir por objetivo, licencia y cadena de herramientas. A continuación, una tabla comparativa orientada a decisión; no pretende ser exhaustiva, sí representativa del estado del arte en SLM.
| Familia / Modelo (referencia) | Tamaños típicos SLM | Licencia / Disponibilidad | Enfoque y notas | Runtimes habituales |
| Google – Gemma 3 | 1B, 4B (también 12B/27B) | Open weights (página oficial y HF) | Equilibrio calidad/eficiencia; buena base para RAG local y asistentes | vLLM, llama.cpp, Ollama, MLX |
| Meta – Llama 3.2 / 4 | 1B, 3B (edge); 4 aporta variantes | Open weights (HF) | Ecosistema amplio, modelos 1B/3B muy extendidos en ondevice | vLLM, llama.cpp, Ollama |
| Microsoft – Phi4 mini | 3.8B | Open weights / acceso amplio | Latencia baja y buen reasoning ligero; ideal para copilotos acotados | vLLM, llama.cpp, Ollama |
| Alibaba – Qwen 2.5 | 0.5B, 1.5B, 3B, 7B | Open weights | Granularidad de tamaños; variantes instruct/coder/math | vLLM, llama.cpp, Ollama |
| Mistral – Ministral/Small | 3B, 8B | Open weights | Línea europea eficiente; 3B/8B como caballos de batalla | vLLM, llama.cpp, Ollama |
| IBM – Granite 4.0 Nano | ~0.35B, ~1B | Apache2.0 (open weight) | Híbrido Mamba/Transformer con firma criptográfica del modelo | vLLM, llama.cpp |
| OpenBMB – MiniCPM | 2.4B (texto), 2.8B (multimodal) | Open weights | Multimodal ligero para OCR/visión en Edge | vLLM, llama.cpp, OpenVINO |
| TinyLlama | 1.1B | Open weights | Altísima frugalidad para PoC y pipelines de cuantización | llama.cpp, Ollama |
Observación práctica: en la banda 1–4B suelen resolverse la mayoría de los flujos empresariales “no creativos”, especialmente cuando el prompting y el retrieval están bien diseñados. Entre 5–8B aparecen mejoras fiables en comprensión y robustez, a costa de memoria.
Qué habilita realmente a los SLM (bajo el capó)
Tres movimientos técnicos explican el salto. Primero, modelos y datos más curados: menos ruido y mejores objetivos de entrenamiento permiten “sacar más jugo” por parámetro.
Segundo, eficiencia arquitectónica: híbridos con State Space Models (SSM/Mamba) reducen el uso de memoria en inferencia y mantienen rendimiento en contexto largo, lo que abre la puerta a lotes razonables en hardware común.
Tercero, cuantización y compilación: de FP16 a INT8/INT4 con runtimes modernos, el consumo de RAM cae y la velocidad sube, con penalizaciones de calidad gestionables si se evalúa con cuidado. El resultado: pasar de “necesito una GPU de centro de datos” a “me vale una GPU de portátil” para muchísimos casos.
Huella de memoria en la práctica
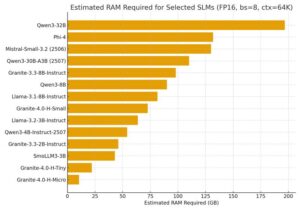
Para tomar decisiones hay que mirar números. A continuación, reproducimos, en formato neutral, la estimación de RAM para un conjunto representativo de SLM en condiciones de producción (FP16, batch size = 8 y contexto = 64K). Este gráfico muestra cómo cambian las exigencias entre familias y tamaños.
En la banda micro (2–4B), diseños orientados a eficiencia pueden moverse en decenas bajas de GB, habilitando despliegues en máquinas de trabajo. En tiny (5–8B) el salto de memoria es notable, pero sigue siendo razonable con estaciones de trabajo modernas o servidores ligeros. En small (9–32B) entramos en cifras que exigen planificación específica de hardware y, en muchos casos, justifican offload a servicios gestionados o particionamiento por políticas.
Sobre cuantización: en INT8 o incluso INT4 los requisitos bajan de forma significativa. La elección del runtime (llama.cpp, vLLM, MLX, OpenVINO) y del hardware (GPU/CPU/Metal) determina el perfil final; por ello, conviene medir con workloads reales antes de fijar la arquitectura.
¿Cuándo SLM y cuándo LLM grande?
La respuesta útil es “ambos, pero con criterio”. Los SLM brillan cuando hay datos sensibles que no deben salir del perímetro, cuando hay latencia dura en el loop de negocio, cuando el coste por consulta debe ser predecible y cuando el problema está acotado por dominio.
El LLM grande entra en escena cuando buscamos cobertura abierta de conocimiento, multimodal pesado, síntesis creativa o razonamiento profundo sostenido. El patrón que recomendamos en Raona es híbrido: el SLM atiende por defecto, el enrutador promueve al LLM grande según política (umbral de confianza, tipo de tarea, ventana de contexto o SLA), y ambos quedan integrados bajo una misma capa de observabilidad, guardrails y governance.
Operacionalización: del portátil al CPD (y al Edge)
Poner SLM en producción implica disciplina. Versionamos pesos y prompts en un registro de modelos, aplicamos verificación/firmas cuando el proveedor las ofrece, pasamos por escaneo/atestación antes de promoción y mantenemos telemetría unificada (latencia, coste por 1K tokens, winrate frente a conjuntos de evaluación propios). En entornos industriales, la topología edge adopta un gateway local que aplica control de acceso y policy routing y que registra las decisiones para auditoría. Con esto conseguimos repetibilidad, reversión simple y trazabilidad, los tres pilares que piden los equipos de CISO y Compliance.
Arquitecturas SLM en 2025: cómo están construidos y por qué importa
Aunque cada familia evoluciona a su ritmo, hay convergencias claras que explican el buen desempeño de los SLM:
- Backbone común (patrón dominante). La mayoría adopta un Transformer decodificador (auto-regresivo) con RoPE (posicional rotatorio), RMSNorm y FFN tipo SwiGLU/Gated-MLP. Para reducir latencia y memoria emplean Grouped-Query o Multi-Query Attention (GQA/MQA) —una sola key/value por grupo o por cabeza— que minimiza el tamaño del KVcache sin degradar en exceso la calidad. Estas piezas, combinadas con kernels fusionados y runtimes modernos (vLLM, llama.cpp, MLX/Metal, OpenVINO), explican por qué modelos de 1–4B ya son útiles en CPUs potentes o GPUs de portátil.
- Optimización de contexto y caché. La gestión del KVcache (paginado, compresión, reutilización interturno) y técnicas de RoPEscaling permiten ampliar ventanas de contexto manteniendo latencias controladas. En entornos de producción esto se complementa con speculative decoding y batching dinámico del servidor.
A partir de ese terreno común, distintas familias añaden matices arquitectónicos y de entrenamiento:
Llama 3.2 (1B/3B)
- Arquitectura. Transformer decodificador con RoPE, RMSNorm, GQA y SwiGLU en el bloque FFN. El diseño se centra en eficiencia en tamaños muy pequeños, manteniendo compatibilidad con toolchains de despliegue abiertos.
- Implicaciones. Excelente base para edge/ondevice y servicios locales: tamaño de KVcache contenido, compatibilidad madura con llama.cpp/vLLM/Ollama, y cuantización estable a INT8/INT4 para reducir aún más RAM sin romper demasiado la calidad.
Gemma 3 (1B/4B)
- Arquitectura. Transformer decodificador eficiente con RoPE y variantes de GQA/MQA, entrenamiento curado y checkpoints orientados a cuantización. La familia equilibra calidad y frugalidad en los tamaños 1B y 4B.
- Implicaciones. Muy apto para RAG local y asistentes de dominio: buena estabilidad tras cuantización, soporte de vLLM/llama.cpp/MLX, y latencias competitivas en GPUs de consumo.
Phi4 mini (≈3.8B)
- Arquitectura. Transformer decodificador con receta de entrenamiento fuertemente curada/sintética, RoPE, normalizaciones modernas y ajustes de alignment orientados a razonamiento ligero.
- Implicaciones. Punto dulce para copilotos acotados: relación calidadlatencia destacada, buen rendimiento en Azure/HF/Ollama, y soporte habitual de cuantización para despliegues en estaciones de trabajo.
Qwen 2.5 (0.5B/1.5B/3B/7B)
- Arquitectura. Transformer decodificador con RMSNorm, SwiGLU y GQA, tokenizador BPE y recetas de entrenamiento escalables que permiten granularidad fina de tamaños.
- Implicaciones. Familia versátil para MVP: elegir 0.5–1.5B para PoC ultraligera, o 3–7B cuando hace falta margen extra de comprensión, manteniendo compatibilidad con vLLM/llama.cpp/Ollama.
Mistral (3B/8B “Small/Ministral”)
- Arquitectura. Línea centrada en eficiencia del Transformer con GQA y kernels optimizados; continuidad con prácticas de Mistral 7B en gestión eficiente de contexto e inferencia.
- Implicaciones. Buenos caballos de batalla cuando se busca equilibrio entre calidad y coste en 3–8B, con ecosistema europeo sólido y soporte en runtimes populares.
Granite 4.0 Nano (≈0.35B/≈1B)
- Arquitectura. Híbrido Mamba2/Transformer: capas de State Space Models (SSM) intercaladas con capas Transformer para reducir uso de memoria y mantener rendimiento en contexto largo. Los checkpoints incorporan verificación criptográfica para garantizar procedencia e integridad.
- Implicaciones. Excelentes para edge industrial y onprem con requisitos de gobernanza: bajísimo consumo de RAM a igualdad de contexto, facilidad para operar en vLLM/llama.cpp/MLX, y encaje natural en pipelines con políticas de firma/atestación.
Patrones de despliegue recomendados (de MVP a producción)
- MVP ondevice (portátil o NUC con GPU): Llama 3.21B/3B o Gemma 31B cuantizados a INT4/INT8, server Ollama/llama.cpp, evaluación con promptpacks y conjuntos internos.
- PoC departamental (servidor ligero): Phi4mini o Qwen 2.53B/7B en vLLM con batching dinámico y telemetría de latencia/coste; RAG local con índice embebido.
- Producción regulada onprem/edge: Granite 4.0 Nano o Mistral 3B/8B bajo registro de modelos, firmas/atestación cuando disponibles, canary de pesos y enrutado híbrido a LLM grande por política (tipo de tarea, umbral de confianza, SLA de latencia).
Conclusión Raona
Los SLM no son una moda; son una herramienta pragmática para llevar la IA donde están los datos y donde ocurre el trabajo. En 2025 podemos ejecutar asistentes útiles en portátiles y en CPD propios con costes contenidos y latencia mínima, sin renunciar a modelos grandes cuando el problema lo pida. La clave es el diseño híbrido con gobierno: elegir el tamaño por el valor que aporta y operar con criterios de ingeniería, no de hype.
Esta fue la quinta entrega de la serie «Hablemos de…». Si quieres explorar un piloto openprem, comparar opciones de modelos o medir el TCO real de tu caso, podemos ayudarte a diseñar la arquitectura, instrumentar métricas y ponerlo en marcha en semanas.
Fuentes y referencias
- Google DeepMind — Gemma 3: https://deepmind.google/models/gemma/gemma-3/
Gemma (landing): https://deepmind.google/models/gemma/
- Meta — Llama 3.2 (blog oficial): https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
Llama 3 (modelos): https://www.llama.com/models/llama-3/
Llama (site): https://www.llama.com/
- Microsoft — Phi4 mini (anuncio): https://techcommunity.microsoft.com/blog/educatordeveloperblog/welcome-to-the-new-phi-4-models—microsoft-phi-4-mini–phi-4-multimodal/4386037
Phi4miniinstruct (HF): https://huggingface.co/microsoft/Phi-4-mini-instruct
- Alibaba — Qwen 2.5 / Qwen 3: https://qwen.ai/
Qwen 3 (site): https://qwen-3.com/en
Qwen 2.5 (repos GitHub): https://github.com/QwenLM/Qwen2.5-Omni
Qwen 2.5VL (GitHub): https://github.com/QwenLM/Qwen2-VL/
- Mistral — Modelos edge (Ministral 3B/8B, Small): https://mistral.ai/models
Documentación de modelos: https://docs.mistral.ai/getting-started/models
- IBM — Granite 4.0 Nano (docs): https://www.ibm.com/granite/docs/models/granite
IBM Think (nota sobre Granite 4.0 Nano): https://www.ibm.com/think/news/granite-4-0-nano-could-change-use-of-ai
- OpenBMB — MiniCPM (texto): https://github.com/OpenBMB/MiniCPM
MiniCPMV (multimodal): https://github.com/OpenBMB/MiniCPM-V
- TinyLlama — repositorio: https://github.com/jzhang38/TinyLlama
- Runtimes de referencia: llama.cpp — https://github.com/ggerganov/llama.cpp
vLLM — https://github.com/vllm-project/vllm
Apple MLX — https://github.com/ml-explore/mlx




