

Por qué este artículo ahora
En los últimos 12 meses el mercado de modelos fundacionales (LLM) ha cambiado más que en los cinco años anteriores. Google ha renovado por completo sus familias Gemini (cerrada/comercial) y Gemma (pesos abiertos), mientras que OpenAI, Anthropic, xAI, DeepSeek, Mistral y Alibaba (Qwen) empujan el estado del arte con nuevos releases, precios agresivos y ventanas de contexto gigantes.
Como partners de Microsoft, en Raona ayudamos a nuestros clientes a aprovechar Azure OpenAI Service y todo el ecosistema de Microsoft Fabric, Power Platform y Azure. Pero el mercado es multivector: entender cómo se posicionan Gemini/Gemma frente a los otros líderes nos permite elegir con datos la mejor pieza tecnológica para cada caso de uso—y, cuando conviene, integrar modelos alternativos mediante arquitecturas híbridas y responsables.
Línea temporal rápida (julio 2024 → julio 2025)
Para poner orden antes de entrar en detalle, aquí va el recorrido mes a mes de los lanzamientos clave de Google y del resto del ecosistema. Úsalo como marco mental: te ayudará a entender por qué ciertos precios o benchmarks aparecen «de golpe» en el mercado.
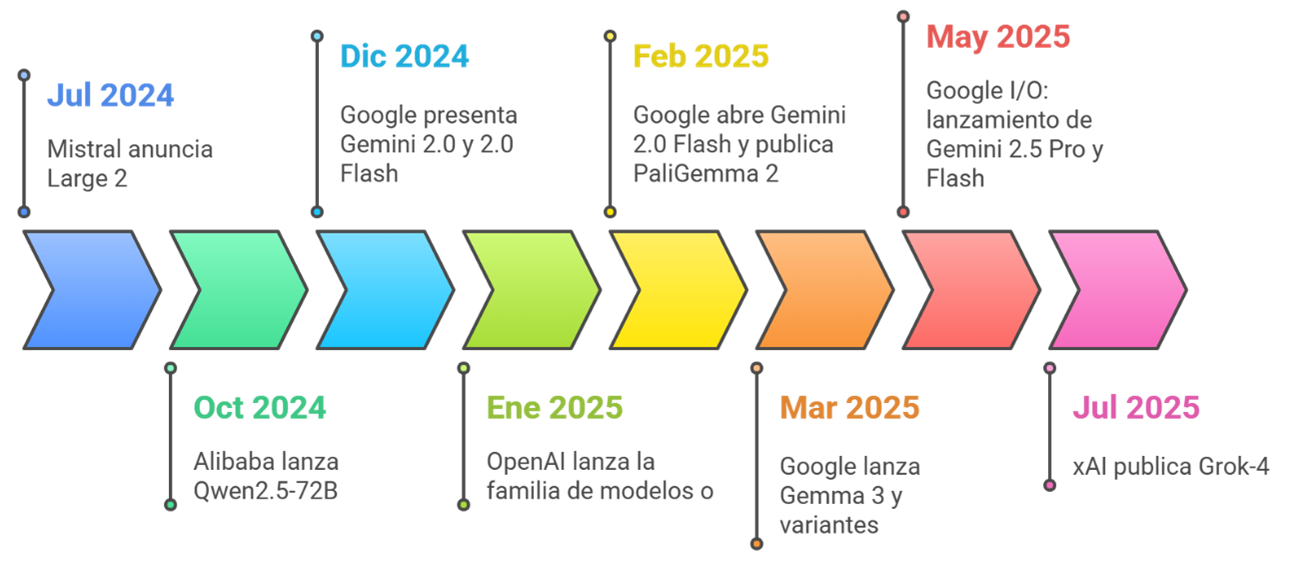
Jul 2024
Arranca el verano con un golpe de efecto: Mistral presenta Large 2. Sigue sin competir al céntimo como DeepSeek, pero se posiciona como el «premium asequible» del mercado: buen rendimiento, 128k de contexto y un pricing que muchos teams aceptan sin demasiado debate.
Ago–Sep 2024
Mientras el hemisferio norte vuelve de vacaciones, DeepSeek empieza a ocupar titulares. Sus versiones V2/V3 abiertas y una API con precios casi simbólicos en China hacen que más de uno se replantee su presupuesto anual. Empieza la conversación sobre si “barato” puede ir de la mano de “bueno”.
Oct 2024
Alibaba libera Qwen2.5‑72B con pesos abiertos y resultados punteros en MMLU. La comunidad open‑source recibe un empujón: ya no sólo se trata de modelos pequeños para juguetear, sino de alternativas serias para producción si tienes la infraestructura.
Dic 2024
Google se mueve fuerte: anuncia Gemini 2.0 y su versión 2.0 Flash. Multimodalidad nativa, ventanas de 1M tokens y los primeros testers jugando con ello. En paralelo, xAI muestra avances de Grok‑2 y deja caer que el verdadero salto vendrá con Grok‑4.
Ene 2025
Año nuevo y OpenAI abre otra línea: los o‑models (o3/o4‑mini), centrados en razonamiento explícito (“thinking tokens”). El mensaje: podemos darte más inteligencia… si aceptas pagar por esos pasos extra de pensamiento.
Feb 2025
Google abre el grifo de Gemini 2.0 Flash y publica PaliGemma 2 (visión+texto, open‑weight). Anthropic no se queda atrás y pule Claude 3.5/3.7 (Sonnet/Haiku), mejorando MMLU‑Pro y ampliando contexto. Febrero se convierte en el mes de las iteraciones rápidas.
Mar 2025
Mes intenso para Google: Gemma 3 llega en tamaños de 1B a 27B, con 128k de contexto y un abanico de variantes: ShieldGemma (seguridad), Gemma 3n (eficiencia). DeepSeek responde con R1 (razonamiento tipo CoT ultra barato) y una renovación de V3. La carrera ya no es sólo por ser el mejor, sino por ser el mejor al precio correcto.
May 2025 (Google I/O)
Se oficializa Gemini 2.5 Pro y Flash. Más razonamiento, audio nativo, “computer use” integrado. Además, Google presenta MedGemma, enfocada a salud: señal clara de especialización por verticales.
Jun 2025
Google afina aún más la línea abierta con Gemma 3n (E2B/E4B): eficiencia, latencia y coste por delante. Ideal para quienes quieren open weights pero sin derretir la GPU.
Jul 2025
xAI lanza Grok‑4 y entra directo al top de Elo y MMLU‑Pro. LMSYS actualiza el Arena: Gemini 2.5 Pro y Grok‑4 se disputan la cima, mientras DeepSeek R1 demuestra que la relación calidad/precio puede seguir bajando. El tablero queda claro: calidad altísima y precios a la baja, pero con estrategias muy diferentes detrás.
Dos familias de Modelos, Dos Estrategias
Gemini y Gemma comparten ADN de investigación, pero responden a problemas y públicos radicalmente distintos. La primera es una línea cerrada, multimodal y con fuerte énfasis en capacidades agenticas (razonamiento paso a paso, ejecución de herramientas, control del entorno digital). La segunda es una familia de pesos abiertos, optimizada para ser afinada, auditada y desplegada en infraestructuras propias o de terceros.
Gemini: núcleo cerrado para experiencias “agentic” de extremo a extremo
Gemini 2.0 y 2.5 introducen un motor pensado para orquestar acciones: interpretar instrucciones complejas, llamar APIs, usar navegadores o aplicaciones («computer use») y devolver resultados en formatos estructurados. Bajo el capó, Google combina:
- Multimodalidad nativa (texto, imagen, audio y vídeo dentro del mismo forward pass), evitando pipelines separados.
- Ventanas de contexto masivas (hasta 1M tokens) y context caching para reducir costes cuando se reutilizan grandes prompts o bases de conocimiento.
- Modos de razonamiento explícitos («Deep Think»/»Thinking tokens») que permiten al modelo generar cadenas de pensamiento largas sin exponerlas al usuario final, optimizando tanto calidad como privacidad.
- Infraestructura gestionada en Vertex AI (SLA, cumplimiento normativo, monitorización) y un pricing granular (Pro vs Flash vs Flash Lite) que equilibra latencia, coste y calidad.
Beneficio para el negocio: Gemini es ideal cuando buscamos resultados consistentes, escalabilidad inmediata y features avanzadas listas para producción (seguridad, auditoría, tool-use integrado). Para un CIO, significa menos ingeniería alrededor del modelo y más foco en la lógica de negocio.
Gemma: apertura, eficiencia y especialización
Gemma 2 y, especialmente, Gemma 3, llevan la filosofía de Google a la esfera open-weight: tamaños desde 1B hasta 27B parámetros, 128k de contexto (excepto el modelo de 1B), y variantes multimodales o específicas de dominio. Técnicamente incorporan:
- Optimizaciones de eficiencia (RoPE escalado, attention con múltiples consultas, quantización amigable) que permiten correr modelos medianos en una sola GPU o incluso en edge.
- Facilidad de fine-tuning (LoRA/QLoRA, PEFT) y de evaluación interna, gracias a licencias permisivas (Apache 2.0) y documentación transparente.
- Derivados especializados: PaliGemma 2 para visión-lenguaje, MedGemma para salud, ShieldGemma para seguridad y Gemma 3n enfocada a latencia baja. Esto evita “forzar” un modelo genérico a contextos regulados o modalities específicas.
Beneficio para el negocio: Gemma permite control total del TCO (Total Cost of Ownership) y de la cadena de valor del dato (on‑prem, soberanía, personalización profunda). Para un CTO o arquitecto de datos, es la base perfecta para construir capacidades diferenciales sin pagar por cada token, a costa de asumir la complejidad MLOps: despliegue, escalado, observabilidad y gobernanza.
Diferencias clave resumidas
- Modelo de entrega: Gemini = API gestionada y propietaria; Gemma = pesos abiertos para self-host o nubes alternativas.
- Capacidades integradas: Gemini trae de serie tool-use, computer-use y guardrails corporativos; Gemma requiere montar ese andamiaje con frameworks externos.
- Coste: Gemini cobra por uso (con tiers y caching); Gemma “no cuesta” en tokens pero exige inversión en infraestructura, seguridad y mantenimiento.
- Velocidad de adopción: con Gemini puedes ir de prototipo a producción en días; con Gemma puedes lograr una solución altamente optimizada y compliant, pero el time-to-value depende de tu músculo técnico.
Gemini maximiza la velocidad y la fiabilidad enterprise «as-a-service», mientras Gemma maximiza la flexibilidad y la propiedad del stack. La elección, por tanto, no es sólo técnica: es estratégica.
Benchmarks que importan (y por qué deberían importarte)
Durante años nos aferramos a siglas como MMLU, GSM8K o HellaSwag. Funcionaban como los “exámenes tipo test” de la IA. El problema: los modelos top ya sacan sobresaliente en la mayoría, así que dejaron de separar realmente a los mejores. Hoy la conversación se ha desplazado a pruebas más difíciles y, sobre todo, más cercanas a lo que hacemos en negocio.
¿Qué mide cada uno?
- MMLU (Massive Multi‑Task Language Understanding): 57 materias académicas (derecho, historia, medicina…). Preguntas tipo test de nivel universitario. Útil para ver cultura general “técnica”. Hoy casi todos los modelos punteros superan el 80%.
- MMLU‑Pro: la versión “sin red”. Preguntas abiertas, razonamiento más profundo y menos pistas. Aquí sí aparecen diferencias reales entre modelos de primera línea.
- GPQA (Graduate‑Level Google-Proof Q&A), modalidad “Diamond”: preguntas de posgrado diseñadas para que no se respondan con un simple copy‑paste de internet. Exige deducción y pasos intermedios.
- AIME / MATH 2024‑25: problemas de matemáticas olímpicas. No sirven para todos los casos de negocio, pero son un buen proxy del “razonamiento simbólico” y la capacidad de manejar cadenas de lógica complejas.
- Chatbot Arena Elo (LMSYS): aquí la comunidad compara modelos a ciegas en duelos 1‑a‑1. Es un ranking “social”: refleja cómo perciben los usuarios la calidad de la conversación, la precisión y el tono. Muy útil para estimar satisfacción real.
- GSM8K y HellaSwag: razonamiento aritmético básico y sentido común. Ya están “resueltos” (≥95% en los líderes), por eso apenas discriminan.
Qué nos dicen los datos recientes:
- Gemini 2.5 Pro y Grok‑4 se sitúan en la parte alta del Elo Arena (≈1450 puntos), lo que indica una experiencia conversacional muy sólida.
- Claude 3.7 / Opus 4 lidera en MMLU‑Pro (más del 87%), es decir, sobresale cuando el reto es entender y razonar sin ayudas.
- DeepSeek R1 logra resultados top‑10 con un coste muchísimo menor: un mensaje claro de que el “precio por inteligencia” está cayendo.
- En el mundo open‑weight, Qwen2.5‑72B roza el 86% en MMLU, y Gemma 3‑27B combina un rendimiento digno con licencias abiertas y tamaños manejables.
La conclusión práctica: elige el termómetro que se parezca a tu problema. Si necesitas conversaciones largas y ricas, mira Elo. Si tu reto es comprender documentos complejos o tomar decisiones técnicas, mira MMLU‑Pro/GPQA. Para cálculos o planificación rigurosa, mira AIME/MATH. El resto son números decorativos.
Costes y ventanas de contexto: la nueva variable estratégica
Hablar de modelos hoy es hablar de tokens y contexto. Los proveedores han convergido en un lenguaje común: precio por millón de tokens (entrada/salida) y recargos cuando empujamos más allá de cierto umbral de contexto. En paralelo, aparecen mecanismos como el context caching para no volver a pagar lo mismo cada vez que enviamos un prompt gigante.
En lugar de soltar sólo números, veamos qué significan: si vas a analizar contratos de 500 páginas o a mantener una sesión de trabajo continua con tu copiloto, una ventana de 1 millón de tokens puede ahorrarte ingeniería de retrieval. Si, por el contrario, tu patrón es corto y repetitivo, un modelo barato con 64k y buen RAG puede ser suficiente.
A continuación, la tabla con los modelos más citados este año. Esta vez la dejamos como tabla “real” para que puedas leerla de un vistazo y copiarla a tu deck si lo necesitas:
| Vendor | Modelo (2024/25) | Contexto máx. | Precio In / Out (USD · 1M toks) | Licencia |
| Gemini 2.5 Pro | 1M | $1.25 / $10 (≤200k) · $2.50 / $15 (>200k) | Propietaria | |
| Gemini 2.5 Flash | 1M | $0.30 / $2.50 (texto) · $1 audio in | Propietaria | |
| Gemma 3 27B (open) | 128k | 0 $ en tokens (pagas tu propia infra) | Apache‑2.0 | |
| OpenAI | GPT‑4.1 | ~1M | $3.00 / $12.00 | Propietaria |
| OpenAI | o3 / o4‑mini (thinking) | ≥200k [1] | Tier similar a 4.1 (no divulgado públicamente) | Propietaria |
| Anthropic | Claude 3.7 Sonnet | 200k | $3.00 / $15.00 | Propietaria |
| xAI | Grok‑4 | 256k | $3.00 / $15.00 [2] | Propietaria |
| DeepSeek | R1‑0528 / V3 | 64k | $0.27–0.55 / $1.10–2.19 (cache miss) | MIT |
| Mistral | Large 2 | 128k | $2.00 / $6.00 | Propietaria |
| Alibaba | Qwen2.5‑72B (open) | 32k–128k [3] | 0 $ en tokens (infra propia) | Apache‑2.0 |
[1] OpenAI no publica el detalle exacto para la familia “o”; se infiere por documentación y pruebas de la comunidad.
[2] xAI tampoco ha publicado una tabla oficial; asumimos el mismo tier que GPT/Claude por confirmaciones públicas.
[3] Depende de la variante y de si usas self‑host o el servicio en la nube de Alibaba.
Y ahora, ¿qué hago con estos números?
Más allá de mirar quién es más barato o quién tiene más ceros en la ventana de contexto, lo relevante es cómo impacta eso en tu caso de uso, tu presupuesto y tu riesgo operativo. Pensemos en tres escenarios típicos:
Quieres razonamiento profundo con garantías enterprise.
Proyectos donde un error cuesta dinero o reputación (asesoría legal, decisiones financieras, soporte médico) suelen justificar el premium. Modelos como GPT‑4.1, Claude 3.7 o Gemini 2.5 Pro incluyen controles de seguridad, auditoría y SLAs. Ganarás tiempo de salida a producción y dormirás mejor.
Tu reto es el volumen: millones de interacciones o documentos.
Aquí manda el coste por millón de tokens y la latencia. Gemini 2.5 Flash o DeepSeek R1 permiten procesar a escala sin arruinar el TCO. El truco está en complementar con buenas prácticas: prompts comprimidos, caching, RAG inteligente.
Necesitas control absoluto del dato y personalización extrema.
Sectores regulados, requisitos de soberanía o necesidad de integrar conocimiento propietario a muy bajo nivel empujan hacia Gemma, Qwen o Mistral open. No pagarás por token, pero pagarás en ingeniería: MLOps, seguridad, hardening, observabilidad… Si tienes equipo para sostenerlo, la inversión compensa.
Hoy en día, el precio y contexto son sólo dos piezas del puzzle. Ponlos al lado de la calidad en tus tareas, del riesgo regulatorio y de tu capacidad técnica. Un modelo “barato” que falla en lo crítico es carísimo; uno “caro” que evita semanas de trabajo manual acaba siendo una ganga. Nuestra labor como partner es ayudarte a trazar esa curva de valor y a combinar modelos cuando conviene.
Cómo decidir: el Marco de Evaluación Raona
Tomar la decisión no es marcar casillas, es contar una historia coherente entre tu problema, tus datos y tu capacidad de ejecución. En Raona usamos un marco sencillo de explicar al comité de dirección y lo bastante profundo para que tu equipo técnico no sienta que estamos simplificando de más.
Paso 1: Empieza por el impacto, no por el modelo
¿Qué estás intentando mover? ¿Ingresos, eficiencia operativa, satisfacción del empleado/cliente, cumplimiento normativo? Clasificamos los casos de uso según criticidad y riesgo. Un asistente interno para FAQs no pesa igual que un copiloto que redacta informes legales o que decide sobre créditos.
Paso 2: Traduce el impacto en requisitos técnicos
De ese mapa surgen preguntas técnicas con nombre y apellido:
- ¿Necesitamos razonamiento profundo o respuestas rápidas y baratas? (MMLU‑Pro/GPQA vs throughput en tokens/s.)
- ¿Hay multimodalidad real (imágenes, audio, vídeo) o basta con texto y RAG?
- ¿Cuánta memoria de trabajo requiere el flujo (ventana de contexto, caching) y cuánto podemos delegar en recuperación de información?
- ¿El modelo debe actuar (tool/computer use) o sólo responder?
- ¿Qué latencia es aceptable para la experiencia que queremos ofrecer?
Paso 3: Pon el negocio sobre la mesa
Aquí entra el CFO: ¿pago por uso o invierto en infraestructura? ¿Me puedo permitir un vendor lock‑in si a cambio gano velocidad y SLA? ¿Dónde deben residir los datos (Europa, on‑prem, multi‑cloud)? Evaluamos precio, compliance y roadmap del proveedor: no es lo mismo apostar por un actor que actualiza cada trimestre que por uno que saca un release al año.
Paso 4: Aterrízalo en tu stack Microsoft
Como partners de Microsoft, solemos partir de Azure OpenAI para acelerar (seguridad, Entra ID, Purview, integración nativa). Pero rara vez paramos ahí. Cuando conviene, enrutamos tráfico a otros modelos (Gemini, DeepSeek, Gemma/Qwen self‑host) usando Azure AI Foundry, Prompt Flow, Semantic Kernel o frameworks como LangChain/DSPy. Es el enfoque “Model Router / Ensemble”: el modelo adecuado para cada tarea, sin fricciones para el usuario final.
Paso 5: Gobernar, medir, iterar
Una vez elegido el stack, empieza el trabajo serio: observabilidad, evals continuos, feedback humano, guardrails y seguridad (ShieldGemma, Azure Content Safety, filtros propios). Medimos no sólo precisión técnica, sino métricas de negocio: tiempo ahorrado, errores evitados, satisfacción, conversión. Y ajustamos—modelos, prompts, pipelines—sobre datos reales, no sobre demos.
Resultado: no es “Gemini o Gemma”, “cerrado u open‑weight”; es qué combinación maximiza tu retorno y minimiza tu riesgo en cada etapa del camino. Nosotros ponemos la metodología y el know‑how; tú decides la velocidad a la que quieres llegar.
Recomendaciones accionables
- Mapea tus casos de uso y clasifícalos por criticidad, volumen de tokens y sensibilidad de datos.
- Prototipa rápido con el modelo premium disponible en tu tenant (p. ej., GPT‑4.1 u o4‑mini en Azure OpenAI) y mide calidad/coste reales.
- Introduce modelos alternativos donde el ROI sea claro: Gemini 2.5 Flash para tareas multimodales baratas; DeepSeek R1 para reasoning de alto volumen; Gemma/Qwen para cargas on‑prem.
- Implementa observabilidad y evaluación continua (evals automáticos, métricas de negocio, feedback humano).
- Diseña un plan de gobernanza y seguridad: clasificación de prompts/datos, políticas de PII, guardrails y filtros (ShieldGemma, Azure Content Safety, etc.).
Cómo te ayudamos desde Raona
- Estrategia y selección de modelo: alineamos KPIs de negocio con métricas técnicas (MMLU-Pro, Elo, coste).
- Implementación en Azure: integración de Azure OpenAI y otros proveedores mediante Azure AI Foundry, Data Lakehouse (Fabric) y Power Platform.
- Arquitecturas híbridas y responsables: enrutamiento inteligente, RAG seguro, agentes controlados y MLOps.
- Optimización de costes: caching, batching, pruning de prompts, embeddings eficientes.
- Formación y change management: adopción de copilotos, gobierno del dato y cultura AI-first.
Próximos pasos
¿Quieres una evaluación comparativa personalizada (benchmarks + costes simulados para tu volumen)? ¿O un piloto en 4 semanas con tu documentación interna y un copiloto seguro?
Hablemos.
En Raona convertimos el hype en resultados medibles.
?¡Descárgate mi guía práctica para integrar la IA en tu empresa!




