
En esta nueva entrega de nuestra serie «Hablemos de», exploramos una de las novedades que puede influir de forma más significativa en la evolución de la búsqueda semántica empresarial: Google Embeddings 2. Con este avance, Google refuerza una dirección cada vez más clara en el mercado: el paso desde sistemas centrados únicamente en texto hacia modelos capaces de trabajar con información multimodal en un espacio semántico unificado.
En este artículo analizaremos qué cambia realmente, por qué esta evolución resulta relevante para organizaciones que están impulsando asistentes, buscadores internos o iniciativas de IA generativa, y qué oportunidades abre para construir una nueva generación de plataformas de conocimiento empresarial.
El fin de la «arquitectura de parches» en IA
Para cualquier estratega de datos, la implementación de Inteligencia Artificial en el entorno corporativo ha estado plagada de lo que denominó «arquitectura de parches». Hasta ahora, gestionar un ecosistema de datos heterogéneo requería silos técnicos: un modelo para texto, otro para catálogos visuales y un costoso paso intermedio de transcripción (como Whisper) para poder «leer» el audio. Esta fragmentación no solo infla los costos operativos, sino que degrada la fidelidad de la información en cada traducción entre modelos.
El 10 de marzo, Google presentó gemini-embedding-2-preview, una solución que marca el fin de estos pipelines fragmentados. Al ser un modelo nativamente multimodal, unifica estas dimensiones en un solo espacio vectorial. No obstante, como consultor, mi primer aviso es de carácter estratégico: al tratarse de una versión «preview», las organizaciones deben anticipar posibles ajustes en el comportamiento del modelo antes de su Disponibilidad General (GA). Estamos ante el primer paso hacia una infraestructura de datos verdaderamente coherente.
Un solo espacio vectorial para cinco realidades: La unificación total
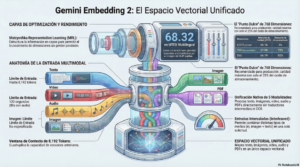
El avance fundamental de Gemini Embedding 2 radica en su espacio vectorial unificado. Tradicionalmente, una imagen y un párrafo de texto habitaban universos matemáticos distintos. Con este modelo, el texto, las imágenes, el vídeo, el audio y los documentos PDF se mapean directamente en las mismas coordenadas semánticas.
Desde una perspectiva de arquitectura, esto elimina el overhead técnico de coordinar múltiples modelos (como CLIP para imágenes o modelos especializados para PDF). La pérdida de información se reduce drásticamente porque el modelo «entiende» la relación entre un diagrama técnico en un PDF y una consulta de voz de un operario sin necesidad de conversiones intermedias.
«Nuestra meta es traer todas las modalidades – texto, imágenes, vídeo, audio y documentos – a un mismo espacio de representación vectorial sin necesidad de ninguna traducción intermedia.» Logan Kilpatrick, líder de Relaciones con Desarrolladores en Google DeepMind.
Audio Nativo: Adiós al intermediario de la transcripción
Uno de los puntos más disruptivos es el procesamiento de audio nativo. En el enfoque tradicional, buscar en grabaciones de soporte o juntas directivas requería un pipeline de Speech-to-Text. Si la transcripción fallaba por tecnicismos o ruido ambiental, el sistema de búsqueda quedaba ciego.
Gemini Embedding 2 procesa las ondas sonoras directamente en vectores . Esto no solo preserva matices acústicos que el texto ignora, sino que ofrece una reducción de latencia de hasta el 70% al eliminar el paso de transcripción. Para una empresa con miles de horas de audio, esto transforma un archivo estático en un activo de conocimiento accionable de forma casi instantánea.
La infraestructura Matryoshka: El «punto dulce» entre calidad y costo
El almacenamiento de vectores es un factor crítico de ROI. Google ha implementado Matryoshka Representation Learning (MRL), una técnica que permite truncar los vectores sin sacrificar significativamente la precisión. Imagine una muñeca rusa: la información más vital reside en las dimensiones iniciales.
El modelo genera vectores de hasta 3,072 dimensiones, pero permite su uso en configuraciones menores. Mi recomendación técnica para la producción empresarial es:
- 3,072 dimensiones: Reservado para casos de alta precisión técnica, legal o científica.
- 768 dimensiones: El «sweet spot» o punto dulce. Ofrece una calidad cercana al pico máximo con una fracción del peso.
Al optar por 768 dimensiones, 1 millón de vectores requieren apenas 3 GB de almacenamiento, frente a los 12 GB de la versión completa. Es una optimización del 75% en infraestructura de base de datos vectorial sin una degradación perceptible en la experiencia del usuario.
Dominio en Benchmarks: Precisión frente a Relevancia
Gemini Embedding 2 no solo es versátil; es superior en métricas de rendimiento real. Es crucial distinguir entre «Relevancia» (encontrar documentos relacionados) y «Accuracy» (identificar y rankear el documento exacto en la primera posición). Mientras que modelos como OpenAI muestran buena relevancia, Gemini sobresale en precisión quirúrgica.
| Tarea de Recuperación | Gemini Embedding 2 | Amazon Nova 2 | Voyage Multimodal 3.5 |
| Texto-a-Vídeo (Accuracy) | 68.8 | 60.3 | 55.2 |
| Texto-a-Imagen (Accuracy) | 93.4 | 84.0 | 91.0 (aprox.) |
Además de liderar en tareas visuales, el modelo ocupa el primer lugar en el ranking MTEB Multilingual (100+ idiomas) y el MTEB Code, lo que lo posiciona como la herramienta definitiva para organizaciones globales y equipos de ingeniería.
Casos de Uso Estratégicos: Del E-commerce al Descubrimiento Legal
- Búsqueda Visual en E-commerce: Permite que un usuario suba una foto de una pieza de repuesto y el sistema la localice no por etiquetas, sino por similitud vectorial con el inventario físico.
- Discovery Legal y Cumplimiento: Plataformas como Everlaw han reportado una mejora del 20% en el recall. El sistema puede cruzar simultáneamente vídeos de declaraciones, PDFs escaneados y correos electrónicos en una sola consulta.
- RAG Enriquecido: A diferencia del RAG tradicional que solo extrae texto, este modelo permite recuperar información basada en el contexto visual de tablas y diagramas dentro de manuales complejos.
Consideraciones Críticas para el CIO: Roadmap y Limitaciones
Como toda innovación, actualmente existen ciertos riesgos y restricciones técnicas que se deben considerar antes de iniciar un proyecto de migración:
- Incompatibilidad de Espacios: Los espacios vectoriales de la versión anterior (001) y la versión 2 son incompatibles. Actualizar requiere re-indexar toda la base de datos. Para mitigar el impacto financiero, las empresas deben utilizar el Batch API, que ofrece un descuento del 50% ($0.10/M tokens) frente al precio estándar de $0.20/M. Para millones de vectores, el Batch API es la única ruta fiscalmente responsable.
- Límites de Ingesta por Solicitud: Es vital diseñar pipelines que respeten los límites de la arquitectura:
- Texto: 8,192 tokens (inferior a los 32K de Voyage 3.5, un competidor fuerte en contextos extensos y «negativos difíciles»).
- Media: Máximo de 6 imágenes, 128s de vídeo, 80s de audio y 6 páginas de PDF por petición.
- Optimización via task_type: Para alcanzar el rendimiento de los benchmarks, el modelo requiere el parámetro task_type. Etiquetas como FACT_VERIFICATION o CODE_RETRIEVAL_QUERY ajustan los pesos del modelo para optimizar la recuperación según el caso de uso.
Hacia una empresa que «entiende» todo su contenido
Gemini Embedding 2 representa el paso de una IA que «lee» a una IA que «observa y escucha». Al unificar audio, vídeo, imágenes y documentos en una sola arquitectura, Google ha simplificado drásticamente el mapa de ruta para las empresas que buscan valor en sus datos no estructurados.
En Raona ayudamos a las organizaciones a convertir estas capacidades en soluciones reales de negocio, diseñando estrategias y arquitecturas de IA que conectan búsqueda, conocimiento y experiencia de usuario con criterios de escalabilidad, gobierno y valor. Porque el reto ya no es solo incorporar más inteligencia, sino hacerlo de forma útil, segura y alineada con la realidad documental de cada empresa.




