

Cuando implementamos un proyecto de Paperless en Raona, uno de los puntos del análisis previo que genera mayor preocupación en el cliente al analizar el ciclo de vida del documento es buscar una forma viable de migrar todo el contenido histórico al entorno de SharePoint en Microsoft 365 sin que ello suponga un exceso de trabajo manual. El tiempo y los recursos que puede conllevar esta labor no es para nada despreciable, dado que suele requerir categorizar y extraer información del contenido de documentos que muchas veces sólo se han escaneado como imágenes y no presentan ninguna estructura homogénea.
Las necesidades por cubrir durante el proceso de migración masiva a SharePoint suelen encajar con algunas de estas problemáticas, que posteriormente seguirán activas para aplicarse a los nuevos documentos que se generen derivados del proceso de digitalización documental:
- Extracción de información de los documentos que se pueda incorporar como metadatos de las bibliotecas de SharePoint.
- Categorización de los documentos según la taxonomía definida y asignación de los Content Types
- Cumplimiento de las políticas de seguridad y protección de la información, aplicando las etiquetas de confidencialidad y retención establecidas e integrándose con Microsoft PurView.
- Transformación de los contenidos para generar nuevas plantillas actualizadas que sustituyan los formatos obsoletos y homogeneizarlos.
- Automatización de procesos derivados de la extracción de información de los documentos, que pueden ir desde alertas para la revisión del contenido a integraciones de datos con el CRM o el ERP corporativos.
La Inteligencia Artificial se focaliza en el conocimiento del usuario
Una de las opciones que desde hace años está sobre la mesa es la posibilidad de usar servicios de Inteligencia Artificial para realizar esta tarea, dado el ahorro de costes de implementación derivados de que la documentación y los servicios de IA se han desplazado a la nube. Esto permite automatizar el procesamiento masivo de la documentación usando los algoritmos IA de digitalización OCR, selección de patrones de contenido y NLP para extraer la información. Pero salvo casos muy concretos, cuesta justificar la elevada inversión en tiempo y recursos requerida.
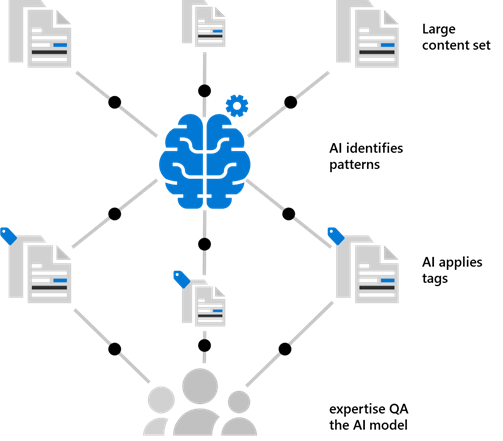
Modelo IA tradicional
Este es el gran problema de los algoritmos de IA: hay que desarrollar y entrenar un modelo a medida, nutrirlo de un dominio de información amplio y dedicar tiempo a supervisar el resultado para garantizar que trabaja adecuadamente. Esto suele ser una labor casi artesanal de expertos en Machine Learning que cargan grandes volúmenes de datos y analizan los resultados para iterar el modelo durante meses. Y esto es algo que impacta negativamente en uno de los valores más preciados de los proyectos de Paperless: un Time to Market (T2M) reducido que facilite la transición del proceso documental a su nuevo ciclo de vida digital.
Sabedor que el gran negocio de los servicios de IA no acaba de alcanzar el volumen deseado, Microsoft dio un paso más en su integración de la Inteligencia Artificial con sus productos en el evento Ignite 2019, donde presentó el Project Cortex. Básicamente, consiste en añadir una nueva capa de abstracción a los algoritmos de IA que los acerque a necesidades concretas de la gestión del conocimiento partiendo de la experiencia de los usuarios. Resumiendo, se trata de pedir a los usuarios que definan la información relevante contenida en los documentos para generar modelos que copien esos patrones y lo apliquen masivamente al conjunto de documentación.
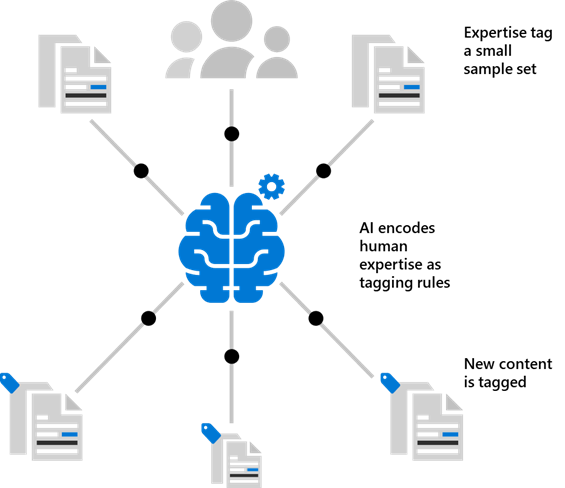
Modelo IA Cortex
Este proyecto se ha materializado en varias soluciones comerciales de Microsoft: por un lado, ha lanzado Viva Topics como un agregador de contenido que mediante la IA muestra al usuario la información relevante a sus necesidades, siendo mucho más eficiente que el clásico buscador. Y por otro, un servicio que resuelve buena parte de las necesidades de la carga masiva de documentos a nuestra solución de Paperless sobre Microsoft 365: SharePoint Syntex.
Sharepoint Syntex, un avance orientado a la documentación
Lanzado recientemente al mercado como solución comercial, SharePoint Syntex aplica la tecnología del Project Cortex a la identificación de información relevante a la documentación corporativa. Centraliza en un sitio de SharePoint llamado Content Center los modelos de IA comunes, que se parametrizan mediante la creación de extractores de contenido y clasificadores de la información por parte de los usuarios. Luego, se activan en las Document Libraries que se desee, aplicando reglas que actúan sobre los documentos que se dejan en ellas.
Las funcionalidades disponibles son variadas y permiten resolver todas las necesidades que se han detallado como claves para cualquier proyecto Paperless:
- Comprensión de documentos permite establecer reglas sobre la información contenida en el texto para que se reconozca como conocimiento atómico a ser explotado y utilizado para categorizar o establecer etiquetas del documento.
- Procesamiento de formularios facilita la extracción de datos de documentos estructurados como facturas o albaranes para incorporarlos cómo metadatos del fichero y que pueden integrarse en otros sistemas o activar flujos de Power Automate a demanda.
- Ensamblaje de contenidos es una funcionalidad aún en preview que permite crear documentos a partir de plantillas predefinidas y rellenarlas con los metadatos que se inserten en un nuevo registro de la biblioteca, generando documentos personalizados automáticamente.
- Aplicar etiquetas de retención y confidencialidad, algo que automáticamente activa las políticas que tengamos definidas en Microsoft Information Protection (MIP) o Microsoft Pureview para garantizar el Compliance de la información corporativa.
- Definir taxonomías automáticamente, gracias a la posibilidad de importar definiciones con el estándar SKOS, que posteriormente podemos mapear con contenidos identificados en los propios documentos.
Claves para el éxito de la IA en un proyecto Paperless
Sin duda, SharePoint Syntex es un avance notable para facilitar la incorporación de los tan anunciados beneficios de la Inteligencia Artificial en el día a día de los usuarios y nuestras primeras experiencias con esta tecnología han sido satisfactorias. Pero en Raona sabemos bien que lograr el éxito depende de incorporar una serie de buenas prácticas a la hora de afrontar el proyecto:
- Definir una estrategia Paperless adecuada al proceso de negocio que vayamos a digitalizar, teniendo en cuenta todo su ciclo de vida y las posibilidades de optimización que nos ofrece la tecnología.
- Poner al usuario en el centro del análisis, incorporando sus preocupaciones y acompañándolo en el proceso de automatización para que no se sienta amenazado por el cambio.
- Definir un buen proceso de Digital Adoption que muestre cómo sacar partido de la tecnología en el día a día y facilite la transición a las nuevas funcionalidades.
- Agilizar el trabajo diario implantando soluciones que mejoren la productividad e incrementen la satisfacción del usuario con un Modern Workplace
- Tener en cuenta que no existe la magia en el mundo de la Inteligencia Artificial: requiere compromiso, tiempo y paciencia para conseguir que los modelos maduren y sean tan autónomos cómo esperamos.
Como siempre, en Raona estaremos encantados de comentar vuestras inquietudes sobre SharePoint Syntex y explorar las colaboraciones que puedan ayudar a hacer de la tecnología una herramienta de productividad y optimización de los procesos. ¿Hablamos?




