
Qwen3-Coder es el modelo de codificación más avanzado de Alibaba/Qwen AI, anunciado el 22 de julio de 2025. Se define con una arquitectura basada en Transformer decoder‑only con Mixture‑of‑Experts (MoE): 480 B parámetros totales y 35 B activos por token, con top‑k gating y balanceo global para especializar expertos. Incorpora GQA en la atención, RoPE extendido con YaRN, y mecanismos como Dual Chunk Attention y Attention Backward Fusion (ABF) para sostener contextos largos sin perder estabilidad. Sobre esa base, el modelo automatiza flujos completos de desarrollo: lee repositorios, genera código, ejecuta y valida pruebas, y corrige errores.
En este artículo te explicamos, con rigor técnico y sin caer en el hype, por qué importa, cómo funciona y qué implica para equipos de producto y tecnología.
Qwen3-Coder: un digno contendiente
En 2023 Alibaba ya había mostrado sus cartas con Qwen y las primeras variantes centradas en código. Aquello fue el preludio: el verdadero salto llega en 2025 con Qwen3, una familia de modelos que reestructura la arquitectura, el preentrenamiento y el razonamiento. Sobre esa base aparece Qwen3-Coder, pensado explícitamente para agentes que programan.
Para las empresas —y especialmente para quienes evaluáis proveedores y tecnologías— esto significa dos cosas. Primero, hay una alternativa de pesos abiertos, con licencia Apache 2.0, que compite con lo mejor del mercado propietario. Segundo, hablamos de un modelo que no se limita a autocompletar funciones: orquesta herramientas, navega documentación, ejecuta tests y razona a largo plazo. Nuestra tesis: este tipo de modelos cambiará la forma en que organizamos equipos, tareas y responsabilidades en ingeniería.
Arquitectura: Transformer decoder‑only + Mixture‑of‑Experts, pero con matices
Qwen3-Coder mantiene la filosofía decoder‑only habitual en los grandes modelos de lenguaje, pero incorpora un Mixture‑of‑Experts (MoE) a gran escala: 480 mil millones de parámetros totales con 35 mil millones activos por paso de inferencia (A35B). El enrutamiento se hace vía top‑k gating y se aplica un balanceo de carga global para evitar expertos ociosos y especializar cada bloque en patrones de código diferentes.
Esta aproximación permite mantener una capacidad expresiva muy alta sin multiplicar el coste de inferencia. El patrón ya lo veíamos en el Qwen3-235B-A22B (22B activos) descrito en el paper: múltiples expertos, activación parcial y técnicas de entrenamiento para repartir el tráfico de tokens. Qwen3-Coder expande la idea y la adapta al dominio de código, donde la diversidad de lenguajes, frameworks y estilos exige especialización interna.
En la capa de atención se mantienen los componentes modernos del ecosistema Qwen3: GQA (Grouped Query Attention) para eficiencia, RoPE extendido con YaRN para manejar secuencias largas y mecanismos como Dual Chunk Attention y Attention Backward Fusion (ABF) para estabilizar el entrenamiento con contextos de cientos de miles de tokens.
Contexto largo de verdad: 256K tokens nativos y hasta 1M extrapolados
El contexto largo no es un detalle menor en un modelo orientado a código. Un repositorio real, con múltiples módulos, documentación y pruebas, exige ventanas grandes o estrategias de recuperación complejas. Qwen3-Coder ofrece 256K tokens nativos y permite llegar a 1 millón de tokens mediante extrapolación (basada en técnicas tipo YaRN). Esto abre la puerta a flujos donde el modelo lee issues, analiza archivos, sugiere cambios y valida resultados en una sola pasada o con menos fragmentación.
No obstante, hay un coste: manejar esos contextos implica memoria, latencia y soluciones creativas de caché. En producción, la clave estará en combinar este músculo con chunking inteligente y retrieval; la buena noticia es que el modelo está preparado para ambos escenarios.
Entrenamiento y post‑entrenamiento: del massive pretraining al Agent RL
El technical report de Qwen3 habla de 36 billones de tokens para la fase base, cubriendo 119 idiomas y dialectos, además de amplias áreas de conocimiento. Qwen3-Coder hereda ese corpus, pero añade una capa específica: unos 7.5 billones de tokens centrados en código (alrededor del 70% de su fase adicional), cubriendo lenguajes modernos, repositorios reales y datos curados para tareas de ingeniería.
El punto diferencial está en el post‑entrenamiento. Aquí Alibaba aplica dos líneas:
- Code RL: refuerzo enfocado a calidad de código, corrección sintáctica y estilo. El modelo recibe feedback sobre compilación, ejecución de tests y métricas objetivas de calidad.
- Long‑Horizon / Agent RL: refuerzo para tareas largas y multi‑paso. No basta con generar una función correcta; el agente debe planificar, llamar herramientas, leer documentación y validar resultados. Este RL orientado a secuencias largas optimiza ese comportamiento.
En paralelo, Qwen3 introduce los modos “thinking” y “non‑thinking” junto a un “thinking budget”. La idea es pragmática: no todas las tareas requieren cadenas de razonamiento extensas. El presupuesto de pensamiento permite ajustar coste/rendimiento, reservando más “reflexión” para problemas complejos (por ejemplo, debugging profundo) y menos para autocompletados triviales.
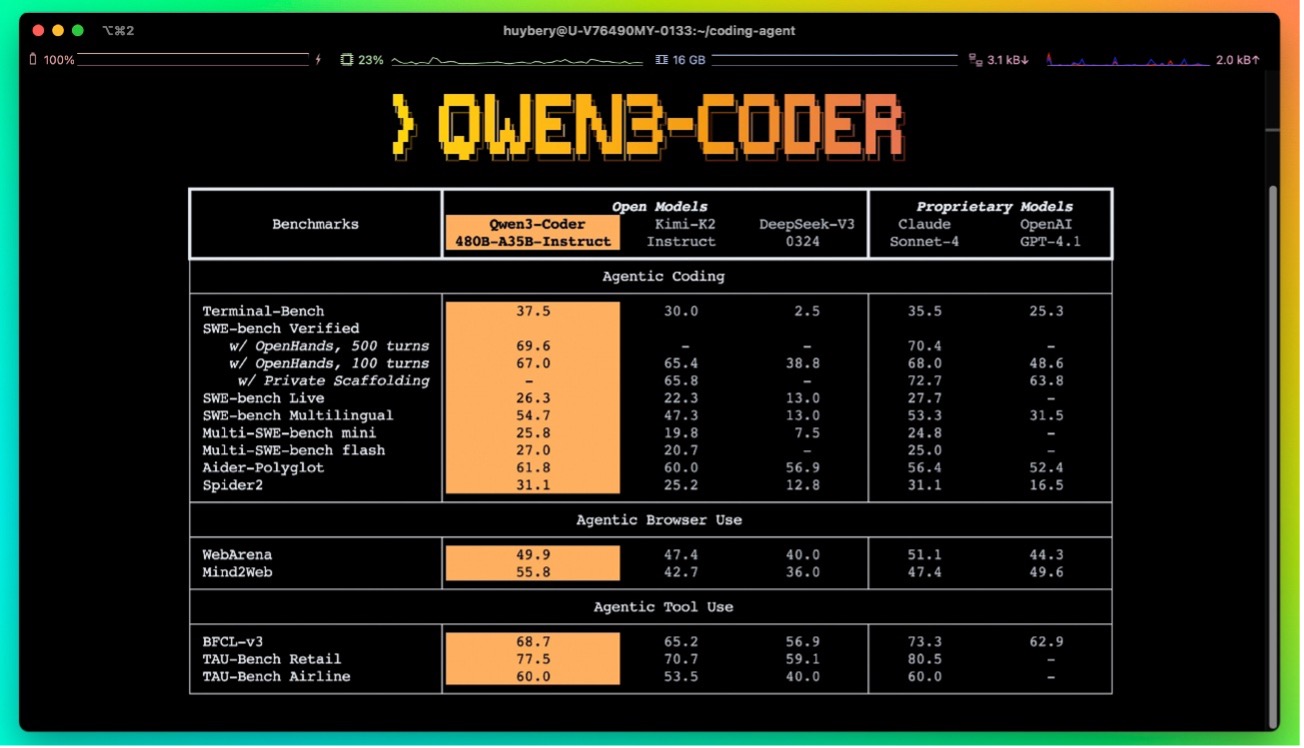
Rendimiento: SWE‑Bench, agentic coding y comparativas con modelos propietarios
Alibaba reporta resultados de estado del arte entre modelos de pesos abiertos en SWE‑Bench Verified, una de las métricas más exigentes porque evalúa la resolución de issues reales con tests automáticos. También muestra liderazgo en tareas de agentic coding, browser‑use y tool‑use —es decir, escenarios donde el modelo debe actuar como un asistente operativo, no solo un generador de texto.
En sus comparativas internas, Qwen3-Coder se acerca al rendimiento de modelos propietarios como Claude Sonnet 4 en tareas de programación.
Como siempre, nuestra recomendación es mirar con lupa las metodologías: la mayoría de estas cifras provienen del proveedor, y conviene esperar evaluaciones independientes para tener un cuadro completo. Aun así, el salto cualitativo frente a sus predecesores (Qwen2.5-Coder) y frente a otros open weights recientes es claro.
Ecosistema y acceso: del CLI a las APIs
La propuesta no llega sola. Alibaba lanzó Qwen Code, una CLI inspirada en Gemini CLI pero optimizada para Qwen3-Coder. Permite orquestar herramientas, ejecutar flujos reproducibles y depurar salidas del modelo de forma más controlada. Además, existe integración con Claude Code, Cline y otros entornos de agentes, así como acceso mediante OpenRouter, DashScope (la API de Alibaba Cloud) y los repositorios habituales (Hugging Face, ModelScope, GitHub), bajo licencia Apache 2.0.
Para equipos que quieran evaluar rápidamente el modelo hay tres caminos:
- API gestionada: ideal para pruebas rápidas y PoCs sin infraestructura propia.
- Ejecución local/cuasi-local: con cuantizaciones (4/8 bits) y KV‑cache optimizado se puede experimentar en hardware limitado, pero ojo con el tamaño del 480B; probablemente necesitaréis infra distribuida o recurrir a variantes más pequeñas cuando estén disponibles.
- Integración en frameworks de agentes: LangChain, LlamaIndex, o herramientas específicas como Cline y la propia Qwen Code, para construir pipelines end-to-end.
Efectos en ingeniería y el negocio
Para los equipos de desarrollo, Qwen3-Coder promete delegar tareas repetitivas —refactors, generación de tests, documentación, revisiones de seguridad básicas— y liberar tiempo para diseño y decisiones arquitectónicas. Para la dirección tecnológica y el negocio, añade una palanca de productividad con menos dependencia de proveedores cerrados, y con la posibilidad de ajustar y auditar el modelo según necesidades de compliance.
El reto no es solo técnico. Introducir agentes con autonomía en entornos productivos implica revisar procesos, permisos, auditorías y límites de actuación. Un modelo que puede leer y modificar repositorios debe ser gobernado con rigor. La buena noticia: la apertura de pesos y tooling facilita construir ese andamiaje de control, en lugar de tratar con cajas negras.
Limitaciones y preguntas abiertas
No todo son victorias. Falta ver evaluaciones independientes amplias; la reproducibilidad de algunos benchmarks será clave para validar claims. El coste de manejar contextos gigantes puede disparar latencias y consumo. Y, como en todo MoE, la distribución de expertos y su especialización pueden generar comportamientos difíciles de interpretar si no se instrumenta adecuadamente la inferencia.
También habrá que observar cómo escalan las variantes más pequeñas —que presumiblemente llegarán— y qué tal se comportan en escenarios edge o on‑premise.
Finalmente, la tensión entre apertura y control seguirá presente: abrir pesos facilita adopción, pero exige más responsabilidad operativa por parte de las empresas.
Landscape competitivo: dónde encaja Qwen3-Coder
El mercado de los modelos para desarrollo de software se está bifurcando entre servicios cerrados con tooling muy pulido (Claude Code, GitHub Copilot Agent) y modelos de pesos abiertos que priorizan soberanía y personalización (DeepSeek-Coder V2, Codestral, Llama 3.1-SWE). Qwen3-Coder se coloca en este segundo grupo, pero con una ambición de rendimiento que lo aproxima a los modelos propietarios líderes.
Claude Code (basado en Claude Sonnet 4) ofrece una experiencia llave en mano: integración profunda con editores, análisis instantáneo de repositorios y un agente que crea pull requests. GitHub Copilot Agent sigue un camino similar, apalancándose en el ecosistema GitHub/Microsoft y en políticas enterprise. En contraste, Qwen3-Coder libera los pesos bajo Apache 2.0 y entrega un CLI abierto (Qwen Code), invitando a que integradores y equipos construyan su propia capa de producto encima.
DeepSeek-Coder V2 y Codestral demuestran que los open weights pueden ser competitivos, pero se quedan en tamaños más modestos, menos enfoque agentic y contextos más limitados. Meta, con Llama 3.1-SWE, apuesta por eficiencia y facilidad de despliegue, no por un MoE gigantesco. Qwen3-Coder busca diferenciarse con escala MoE (480B/35B), contexto largo real (256K→1M) y refuerzo específico para agentes.
Comparativa rápida
| Modelo | Apertura / Licencia | Arquitectura / Tamaño | Contexto nativo | Enfoque «agentic» | Tooling integrado | Acceso / Precio |
| Qwen3-Coder 480B-A35B | Open weight (Apache 2.0) | MoE 480B / 35B activos | 256K (1M extrap.) | Alto (Code RL + Agent RL) | Qwen Code CLI, integraciones comunidad | HF/ModelScope, OpenRouter, DashScope (API) |
| Claude Code / Sonnet 4 | Cerrado (SaaS) | Denso (no revelado) | 200K–1M (según plan) | Alto (browser/tool use nativo) | Terminal, VS Code/JetBrains, repos browser | Pago por token (Anthropic API) |
| GitHub Copilot Agent | Cerrado (SaaS) | Detrás de GPT/Claude/phi, etc. | ~128K–200K[1] | Alto, pero acotado al ecosistema GitHub | Integrado en GitHub, VS Code | Suscripción por usuario/empresa |
| DeepSeek-Coder V2 | Open weight (varias licencias) | Denso ~236B / variantes menores | 32K–128K | Medio (menos RL agentic) | Tooling comunitario | HF/OpenRouter, autoservicio |
| Codestral 22B | Open weight (Mistral License) | Denso 22B | 32K–128K | Bajo/Medio | Extensiones & comunidad | HF/Mistral API |
| Llama 3.1-SWE | Open weight (Meta Llama License) | Denso 8B–70B | 128K | Medio (orientado a SWE, no agentes) | Comunidad, frameworks genéricos | HF/Meta endpoints |
[1] Estimaciones públicas; los proveedores no siempre fijan un número exacto o lo condicionan al plan empresarial.
Recomendaciones estratégicas: ¿cuándo elegir cada uno?
Elige Qwen3-Coder cuando…
- Necesitas soberanía tecnológica: quieres ajustar pesos, cuantizar, afinar RLHF interno o alojar on‑premise/cloud propia.
- Requieres contexto largo real para repos voluminosos, documentación extensa o pipelines complejos.
- Buscas agentes personalizables (tool-use avanzado, integración con tus propias APIs) y aceptas construir parte del tooling.
Elige Claude Code cuando…
- Priorizas time-to-value: necesitas un agente productivo hoy, con UX impecable y soporte enterprise.
- No es crítico abrir pesos ni ajustar el modelo: prefieres pagar por servicio y SLA.
Elige GitHub Copilot Agent cuando…
- Tu operación gira en torno a GitHub y VS Code. Quieres automatizar issues/PRs con mínima fricción.
- La gobernanza y compliance Microsoft/GitHub ya están aprobadas internamente.
Elige DeepSeek / Codestral / Llama SWE cuando…
- Buscas modelos más ligeros para despliegue local o edge.
- El costo de inferencia y la simplicidad importan más que el máximo rendimiento agentic.
- Tu equipo quiere experimentar con varios modelos y hacer model routing según tarea.
Conclusión: más que un autocompletador, un ingeniero asistido por IA
Qwen3-Coder representa un cambio de categoría: de los copilotos puntuales a los agentes que realmente pueden encargarse de bloques completos de trabajo. Nuestra lectura es que este es el tipo de modelo que catalizará nuevas prácticas en ingeniería, desde pipelines auto‑reparables hasta equipos híbridos donde humanos y agentes se coordinan de manera explícita.
La oportunidad está servida, pero también la responsabilidad. En las próximas semanas veremos forks, cuantizaciones, wrappers y tooling construidos sobre Qwen3-Coder. Nuestra recomendación: experimentad, medid, estableced salvaguardas y diseñad procesos donde el valor del agente se maximice sin perder visibilidad ni control.
Si quieres que profundicemos en guías de despliegue, ejemplos de prompts efectivos, o comparativas detalladas con DeepSeek, Code Llama y otros, háznoslo saber: seguimos investigando y compartiendo.
En Raona estamos ayudando a equipos a llevar estos modelos del laboratorio a producción. Si quieres evaluar Qwen3-Coder (u otras alternativas), diseñar un piloto seguro o escalar un agente de desarrollo en tu organización, hablemos: podemos acompañarte desde la arquitectura hasta el change management.nt: adopción de copilotos, gobierno del dato y cultura AI-first.
¡Descárgate mi guía práctica para integrar la IA en tu empresa!