


En esta cuarta entrega de nuestra serie “Hablemos de…”, exploramos uno de los avances más provocadores en inteligencia artificial de los últimos meses: DeepSeek-OCR. Este modelo no solo mejora el reconocimiento óptico de caracteres, sino que redefine cómo los modelos de lenguaje pueden comprimir, recordar y entender la información.
En lugar de depender de miles de tokens de texto, DeepSeek-OCR transforma el texto en imágenes, las comprime y luego las reconstruye con una precisión sorprendente. Un cambio que podría alterar profundamente cómo entendemos el contexto en los sistemas de IA.
Una nueva forma de entender el contexto en modelos de lenguaje
DeepSeek-OCR es una investigación pionera del equipo de DeepSeek-AI que propone una forma completamente distinta de manejar la información textual: en lugar de procesar tokens de texto, convierte el texto en una imagen y lo comprime en un pequeño conjunto de vision tokens.
Luego, un decodificador se encarga de reconstruir el texto original, actuando como un OCR inteligente. Esta metodología permite reducir hasta 20 veces el tamaño del contexto sin perder demasiada precisión, un salto conceptual frente a las limitaciones tradicionales de los LLM.
Arquitectura y componentes principales
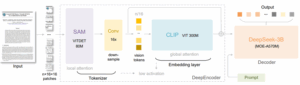
La arquitectura de DeepSeek-OCR se divide en dos partes principales:
- DeepEncoder: un encoder visual diseñado para trabajar con entradas de alta resolución y baja memoria de activación. Combina tres componentes:
- SAM (VITDet 80M): encargado de la atención local, para percibir detalles visuales.
- Conv 16x: un compresor convolucional que reduce 16 veces el número de tokens visuales.
- CLIP (VIT 300M): aporta conocimiento global mediante atención densa.
- DeepSeek-3B-MoE Decoder: un decodificador de mezcla de expertos (Mixture of Experts) con 570 millones de parámetros activados, que transforma los vision tokens en texto, completando el proceso OCR.
Esta combinación permite procesar documentos enteros como si fueran imágenes, codificarlos en muy pocos tokens y reconstruir el texto con alta fidelidad.
Resultados y benchmarks
La imagen anterior resume los hallazgos clave en dos dimensiones: eficiencia de compresión (Fox Benchmark) y rendimiento global en tareas reales (OmniDocBench).
(a) Compresión en Fox Benchmark
En el gráfico de la izquierda, se observa cómo DeepSeek-OCR mantiene niveles de precisión excepcionalmente altos, incluso al aumentar el nivel de compresión. Las barras violetas y celestes representan las configuraciones de 64 y 100 vision tokens respectivamente. A medida que el número de tokens de texto por página crece (de 600 a 1300), la precisión apenas se reduce:
- En configuraciones con menos de 10× de compresión, la precisión se mantiene entre G6% y G8%.
- Incluso al alcanzar una compresión de 20×, el modelo conserva cerca del 60% de exactitud.
Este resultado demuestra la robustez del enfoque óptico, que logra preservar la estructura semántica del documento a pesar de eliminar la mayor parte de la información textual directa.
(b) Rendimiento en OmniDocBench
El gráfico derecho compara el desempeño de DeepSeek-OCR frente a otros modelos multimodales en el benchmark OmniDocBench, donde se mide la distancia de edición (Edit Distance) como indicador de precisión general.
- Las instancias de DeepSeek-OCR (Tiny, Small, Base, Large y Gundam) aparecen en la zona de menor error (ED < 0.25), superando a modelos de referencia como GOT-OCR 2.0, 5-VL o MinerU 2.0.
- Se destaca que con menos de 1000 vision tokens, DeepSeek-OCR alcanza la misma o mejor calidad que modelos que necesitan más de 7000 tokens, lo que evidencia una eficiencia de al menos 7× en reducción de recursos.
Esta visualización ilustra claramente la relación entre número de tokens visuales y rendimiento: el modelo logra resultados de última generación con una fracción del costo computacional. Además, su posición en la gráfica revela la ventaja del nuevo encoder DeepEncoder, representado en rojo, frente a otras familias de encoders (QwenEncoder, InternVLEncoder).
Además, el modelo puede procesar 200.000 páginas por día en una sola GPU A100-40G, lo que lo convierte en una herramienta productiva para generar datos de entrenamiento para otros modelos.
Más allá del OCR: Parsing profundo y comprensión multimodal
DeepSeek-OCR va mucho más allá de las capacidades tradicionales de reconocimiento óptico de caracteres. Su verdadero poder radica en su capacidad para comprender la estructura y el significado completo de un documento, interpretando no solo el texto, sino también su contexto visual y semántico.
Parsing profundo: Más que leer, entender
A diferencia de los sistemas OCR clásicos, que simplemente transcriben texto plano, DeepSeek-OCR es capaz de entender la organización del documento.
Identifica secciones, títulos, tablas, figuras y anotaciones, manteniendo la jerarquía y el flujo lógico del contenido.
Además, el modelo puede transformar información visual en representaciones estructuradas, como:
- Tablas convertidas a formato HTML o Markdown, preservando celdas y relaciones.
- Fórmulas químicas representadas en SMILES o LaTeX.
- Diagramas o figuras técnicas convertidos a descripciones textuales interpretables por humanos o por otros modelos de IA.
Este enfoque integral convierte al modelo en un sistema de parsing semántico profundo, donde cada elemento visual se interpreta en su contexto informativo, no como un objeto aislado.
Comprensión multimodal
DeepSeek-OCR se sitúa en la frontera de la comprensión multimodal: combina visión y lenguaje en un único flujo cognitivo. Esto lo hace especialmente útil en contextos donde los documentos contienen información mixta o no estructurada, como:
- Informes científicos con texto, ecuaciones y diagramas.
- Documentación técnica o financiera con tablas y gráficos.
- Materiales educativos con imágenes, esquemas o mapas conceptuales.
En estos escenarios, el modelo no solo extrae texto, sino que interpreta la intención comunicativa del documento, permitiendo que otros sistemas (por ejemplo, agentes conversacionales o pipelines analíticos) operen directamente sobre conocimiento ya estructurado.
Más allá de la lectura: hacia la comprensión visual del conocimiento
Lo más relevante de este avance es que DeepSeek-OCR abre el camino hacia
modelos que no solo leen, sino que comprenden visualmente el conocimiento. En lugar de separar la percepción (visión) del razonamiento (lenguaje), los fusiona en una única arquitectura coherente. Este principio —ver para entender— redefine la frontera entre los modelos de lenguaje y los de visión, y anticipa una nueva generación de IA verdaderamente multimodal.
La opinión de Andrej Karpathy
El investigador Andrej Karpathy, exdirector de IA en Tesla y referente en aprendizaje profundo, comentó que modelos como DeepSeek-OCR podrían representar un cambio de paradigma: “quizá los LLM nunca debieron leer texto, sino píxeles”.
Su observación apunta a que el uso de píxeles como entrada evita los problemas de los tokenizadores tradicionales (limitaciones de contexto, rarezas de codificación, ineficiencia en textos multilingües o simbólicos). Aunque Karpathy no rechaza los Transformers, sí sugiere repensar el modo en que los modelos interactúan con la información.
Un cambio de paradigma en la IA
DeepSeek-OCR no solo representa un avance en la eficiencia del OCR: plantea una ruptura conceptual en cómo los modelos de lenguaje entienden, almacenan y recuerdan información.
Comparación con los Transformers tradicionales
Los modelos Transformer, desde su concepción, trabajan sobre tokens de texto. Cada palabra o fragmento del texto se convierte en una unidad numérica que el modelo procesa de manera secuencial y contextual. Este enfoque, aunque poderoso, tiene limitaciones claras: la memoria crece cuadráticamente con la longitud del texto, los tokenizadores imponen estructuras artificiales al lenguaje y se pierden elementos visuales como el formato, la disposición o los símbolos no textuales.
DeepSeek-OCR propone un cambio radical: mover la compresión al dominio visual. En lugar de procesar texto lineal, renderiza el contexto como una imagen y lo transforma en vision tokens. Esta aproximación permite capturar la totalidad de la información —texto, estilo, estructura, diagramas o fórmulas— de forma compacta y sin depender de tokenizadores. En esencia, no sustituye a los Transformers, sino que redefine su puerta de entrada a la información.
Implicaciones prácticas
Las consecuencias de este enfoque son profundas:
- Eficiencia computacional: un documento de más de 1.000 tokens puede comprimirse en apenas 100 vision tokens, reduciendo drásticamente los costos de procesamiento.
- Memoria extendida: la posibilidad de representar conversaciones o documentos largos como imágenes abre la puerta a LLMs con memorias prácticamente ilimitadas, donde los contextos pasados se almacenan como visualizaciones comprimidas.
- Universalidad lingüística: al operar en el plano visual, el modelo es independiente del idioma o alfabeto, eliminando los problemas de codificación o mezcla de lenguas.
- Conservación del formato: el diseño, los encabezados, las tablas o diagramas se preservan como parte de la comprensión, no como pérdida de información.
Mirada al Futuro
DeepSeek-OCR sugiere un futuro donde los modelos de lenguaje piensen visualmente. Ya no se trata solo de leer texto, sino de interpretar representaciones completas del conocimiento.
Esta convergencia entre visión y lenguaje podría redefinir la noción misma de “comprensión” en la IA: modelos que recuerdan como los humanos, olvidando progresivamente lo irrelevante mediante compresión óptica, y reteniendo las ideas esenciales en un formato más abstracto y visual.
Palabras al cierre
En Raona, observamos con entusiasmo cómo tecnologías como DeepSeek-OCR redefinen la frontera entre lenguaje y visión. Este tipo de avances inspiran nuevas formas de diseñar soluciones basadas en IA, donde la comprensión contextual y la eficiencia se convierten en pilares fundamentales.
Como especialistas en Inteligencia Artificial, ingeniería digital y transformación inteligente, exploramos continuamente innovaciones que nos permitan ofrecer experiencias más intuitivas, automatizaciones más potentes y sistemas que piensen —y vean— de manera más humana.
¿Qué nuevas oportunidades abrirán modelos que comprimen el conocimiento en imágenes? ¿Cómo puede esta tecnología transformar la manera en que interactuamos con la información?
Nos vemos en la próxima edición de Hablemos de…, donde seguiremos explorando cómo la innovación tecnológica transforma la manera en que pensamos, creamos y colaboramos.
Repositorio oficial: github.com/deepseek-ai/DeepSeek-OCR
Paper técnico: DeepSeek-OCR: Contexts Optical Compression (arXiv:2510.18234)




