
Qwen3-Coder és el model de codificació més avançat de Alibaba/Qwen AI, anunciat el 22 de juliol de 2025. Es defineix amb una arquitectura basada en Transformer decoder‑only amb Mixture‑of‑Experts (MoE): 480 B paràmetres totals i 35 B actius per token, amb top‑k gating i balanceig global per a especialitzar experts. Incorpora GQA en l’atenció, RoPE estès amb YaRN, i mecanismes com a Dual Chunk Attention i Attention Backward Fusion (ABF) per a sostenir contextos llargs sense perdre estabilitat. Sobre aquesta base, el model automatitza fluxos complets de desenvolupament: llegeix repositoris, genera codi, executa i valguda proves, i corregeix errors.
En aquest article t’expliquem, amb rigor tècnic i sense caure en el hype, per què importa, com funciona i què implica per a equips de producte i tecnologia.
En 2023 Alibaba ja havia mostrat les seves cartes amb Qwen i les primeres variants centrades en codi. Allò va ser el preludi: el veritable salt arriba en 2025 amb Qwen3, una família de models que reestructura l’arquitectura, el preentrenament i el raonament. Sobre aquesta base apareix Qwen3-Coder, pensat explícitament per a agents que programen.
Per a les empreses —i especialment per als qui avalueu proveïdors i tecnologies— això significa dues coses. Primer, hi ha una alternativa de pesos oberts, amb llicència Apatxe 2.0, que competeix amb el millor del mercat propietari. Segon, parlem d’un model que no es limita a autocompletar funcions: orquestra eines, navega documentació, executa tests i raona a llarg termini. La nostra tesi: aquest tipus de models canviarà la forma en què organitzem equips, tasques i responsabilitats en enginyeria.
Qwen3-Coder manté la filosofia decoder‑only habitual en els grans models de llenguatge, però incorpora un Mixture‑of‑Experts (MoE) a gran escala: 480 mil milions de paràmetres totals amb 35 mil milions actius per pas d’inferència (A35B). L’encaminament es fa via top‑k gating i s’aplica un balanceig de càrrega global per a evitar experts ociosos i especialitzar cada bloc en patrons de codi diferents.
Aquesta aproximació permet mantenir una capacitat expressiva molt alta sense multiplicar el cost d’inferència. El patró ja el vèiem en el Qwen3-235B-A22B (22B actius) descrit en el paper: múltiples experts, activació parcial i tècniques d’entrenament per a repartir el trànsit de tokens. Qwen3-Coder expandeix la idea i l’adapta al domini de codi, on la diversitat de llenguatges, frameworks i estils exigeix especialització interna.
En la capa d’atenció es mantenen els components moderns de l’ecosistema Qwen3: GQA (Grouped Query Attention) per a eficiència, RoPE estès amb YaRN per a manejar seqüències llargues i mecanismes com a Dual Chunk Attention i Attention Backward Fusion (ABF) per a estabilitzar l’entrenament amb contextos de centenars de milers de tokens.
El context llarg no és un detall menor en un model orientat a codi. Un repositori real, amb múltiples mòduls, documentació i proves, exigeix finestres grans o estratègies de recuperació complexes. Qwen3-Coder ofereix 256K tokens natius i permet arribar a 1 milió de tokens mitjançant extrapolació (basada en tècniques tipus YaRN). Això obre la porta a fluxos on el model llegeix issues, analitza arxius, suggereix canvis i valguda resultats en una sola passada o amb menys fragmentació.
No obstant això, hi ha un cost: manejar aquests contextos implica memòria, latència i solucions creatives de caixet. En producció, la clau estarà a combinar aquest múscul amb chunking intel·ligent i retrieval; la bona notícia és que el model està preparat per a tots dos escenaris.
El technical report de Qwen3 parla de 36 bilions de tokens per a la fase basi, cobrint 119 idiomes i dialectes, a més d’àmplies àrees de coneixement. Qwen3-Coder hereta aquest corpus, però afegeix una capa específica: uns 7.5 bilions de tokens centrats en codi (al voltant del 70% de la seva fase addicional), cobrint llenguatges moderns, repositoris reals i dades curades per a tasques d’enginyeria.
El punt diferencial està en el post‑entrenament. Aquí Alibaba aplica dues línies:
En paral·lel, Qwen3 introdueix els modes “thinking” i “non‑thinking” al costat d’un “thinking budget”. La idea és pragmàtica: no totes les tasques requereixen cadenes de raonament extenses. El pressupost de pensament permet ajustar cost/rendiment, reservant més “reflexió” per a problemes complexos (per exemple, debugging profund) i menys per a autocompletats trivials.
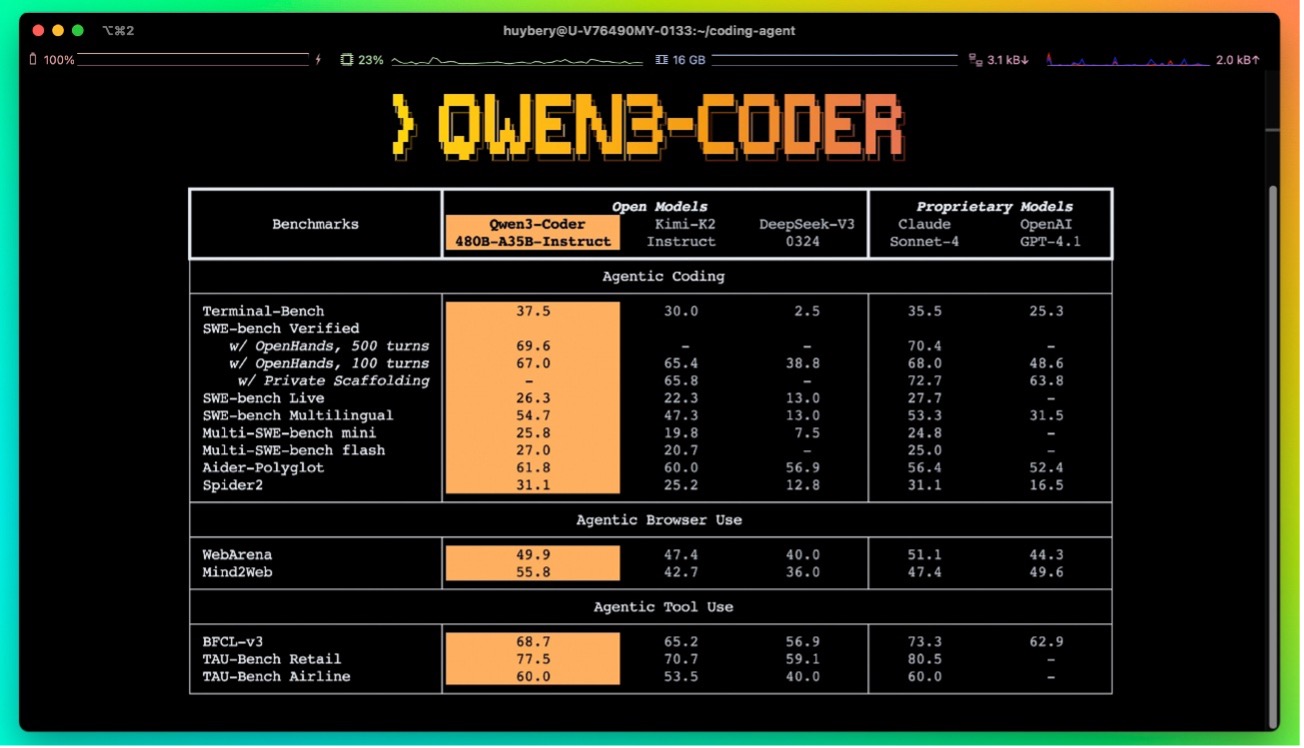
Alibaba reporta resultats d’estat de l’art entre models de pesos oberts en SWE‑Bench Verified, una de les mètriques més exigents perquè avalua la resolució de issues reals amb tests automàtics. També mostra lideratge en tasques de agentic coding, browser‑use i tool‑use —és a dir, escenaris on el model ha d’actuar com un assistent operatiu, no sols un generador de text.
En les seves comparatives internes, Qwen3-Coder s’acosta al rendiment de models propietaris com Claude Sonnet 4 en tasques de programació.
Com sempre, la nostra recomanació és mirar amb lupa les metodologies: la majoria d’aquestes xifres provenen del proveïdor, i convé esperar avaluacions independents per a tenir un quadre complet. Així i tot, el salt qualitatiu enfront dels seus predecessors (Qwen2.5-Coder) i enfront d’uns altres open weights recents és clar.
La proposta no arriba sola. Alibaba va llançar Qwen Code, una CLI inspirada en Gemini CLI però optimitzada per a Qwen3-Coder. Permet orquestrar eines, executar fluxos reproduïbles i depurar sortides del model de forma més controlada. A més, existeix integració amb Claude Code, Cline i altres entorns d’agents, així com accés mitjançant OpenRouter, DashScope (la API de Alibaba Cloud) i els repositoris habituals (Hugging Face, ModelScope, GitHub), baix llicencia Apatxe 2.0.
Per a equips que vulguin avaluar ràpidament el model hi ha tres camins:
Per als equips de desenvolupament, Qwen3-Coder promet delegar tasques repetitives —refactors, generació de tests, documentació, revisions de seguretat bàsiques— i alliberar temps per a disseny i decisions arquitectòniques. Per a la direcció tecnològica i el negoci, afegeix una palanca de productivitat amb menys dependència de proveïdors tancats, i amb la possibilitat d’ajustar i auditar el model segons necessitats de compliance.
El repte no és només tècnic. Introduir agents amb autonomia en entorns productius implica revisar processos, permisos, auditories i límits d’actuació. Un model que pot llegir i modificar repositoris ha de ser governat amb rigor. La bona notícia: l’obertura de pesos i tooling facilita construir aquesta bastimentada de control, en lloc de tractar amb caixes negres.
No tot són victòries. Falta veure avaluacions independents àmplies; la reproducibilidad d’alguns benchmarks serà clau per a validar claims. El cost de manejar contextos gegants pot disparar latències i consum. I, com en tot MoE, la distribució d’experts i la seva especialització poden generar comportaments difícils d’interpretar si no s’instrumenta adequadament la inferència.
També caldrà observar com escalen les variants més petites —que presumiblement arribaran— i que tal es comporten en escenaris edge o on‑premise.
Finalment, la tensió entre obertura i control seguirà present: obrir pesos facilita adopció, però exigeix més responsabilitat operativa per part de les empreses.
El mercat dels models per a desenvolupament de programari s’està bifurcant entre serveis tancats amb tooling molt polit (Claude Code, GitHub Copilot Agent) i models de pesos oberts que prioritzen sobirania i personalització (DeepSeek-Coder V2, Codestral, Flama 3.1-SWE). Qwen3-Coder es col·loca en aquest segon grup, però amb una ambició de rendiment que ho aproxima als models propietaris líders.
Claude Code (basat en Claude Sonnet 4) ofereix una experiència clau en mà: integració profunda amb editors, anàlisi instantània de repositoris i un agent que crea pull requests. GitHub Copilot Agent segueix un camí similar, palanquejant-se en l’ecosistema GitHub/Microsoft i en polítiques enterprise. En contrast, Qwen3-Coder allibera els pesos sota Apatxe 2.0 i lliurament un CLI obert (Qwen Code), convidant que integradors i equips construeixin la seva pròpia capa de producte damunt.
DeepSeek-Coder V2 i Codestral demostren que els open weights poden ser competitius, però es queden en grandàries més modestes, menys enfocament agentic i contextos més limitats. Meta, amb Flama 3.1-SWE, aposta per eficiència i facilitat de desplegament, no per un MoE gegantesc. Qwen3-Coder cerca diferenciar-se amb escala MoE (480B/35B), context llarg real (256K→1M) i reforç específic per a agents.
| Model | Obertura / Llicència | Arquitectura / Grandària | Context Natiu | Enfocament «agentic» | Tooling integrat / Accés |
|---|---|---|---|---|---|
| Claude Code / Sonnet 3.5 | Tancat (SaaS) | Dens (no revelat) | 200K – 1M (segons pla) | Alt (ús natiu del navegador/eines) | Terminal, VS Code/JetBrains, repos browser |
| GitHub Copilot Agent | Tancat (SaaS) | Darrere de GPT/Claude/phi, etc. | ~128K – 200K [1] | Alt, però limitat a l’ecosistema GitHub | Integrat en GitHub, VS Code |
| DeepSeek-Coder V2 | Obert (diverses llicències) | MoE – 236B / variants menors | 32K – 128K | Mitjà (menys RL agentic) | Tooling comunitari |
| Codestral 22B | Obert (Mistral License) | Dens 22B | 32K – 128K | Baix / Mitjà | Extensions i comunitat |
| Llama 3.1-SWE | Obert (Meta Llama License) | Dens 8B – 70B | 128K | Mitjà (orientat a SWE, no agents) | Comunitat, frameworks genèrics |
[1] Estimacions públiques; els proveïdors no sempre fixen un número exacte o el condicionen al pla empresarial.
Tria Qwen3-Coder quan…
Tria Claude Code quan…
Tria GitHub Copilot Agent quan…
Tria DeepSeek / Codestral / Flama SWE quan…
Qwen3-Coder representa un canvi de categoria: dels copilots puntuals als agents que realment poden encarregar-se de blocs complets de treball. La nostra lectura és que aquest és el tipus de model que catalitzarà noves pràctiques en enginyeria, des de pipelines acte‑reparables fins a equips híbrids on humans i agents es coordinen de manera explícita.
L’oportunitat està servida, però també la responsabilitat. En les pròximes setmanes veurem forks, cuantizaciones, wrappers i tooling construïts sobre Qwen3-Coder. La nostra recomanació: experimenteu, mesureu, establiu salvaguardes i dissenyeu processos on el valor de l’agent es maximitzi sense perdre visibilitat ni control.
Si vols que aprofundim en guies de desplegament, exemples de prompts efectius, o comparatives detallades amb DeepSeek, Code Flama i altres, fes-nos-ho saber: continuem investigant i compartint.
En Raona estem ajudant equips a portar aquests models del laboratori a producció. Si vols avaluar Qwen3-Coder (o altres alternatives), dissenyar un pilot segur o escalar un agent de desenvolupament en la teva organització, parlem: podem acompanyar-te des de l’arquitectura fins al change management.nt: adopció de copilots, govern de la dada i cultura AI-first.

Nibaldo Pino Araya

Compartir en Redes Sociales

